Brief introduction into Public BGP Looking Glass servers and how to use them to troubleshoot real-life issues.
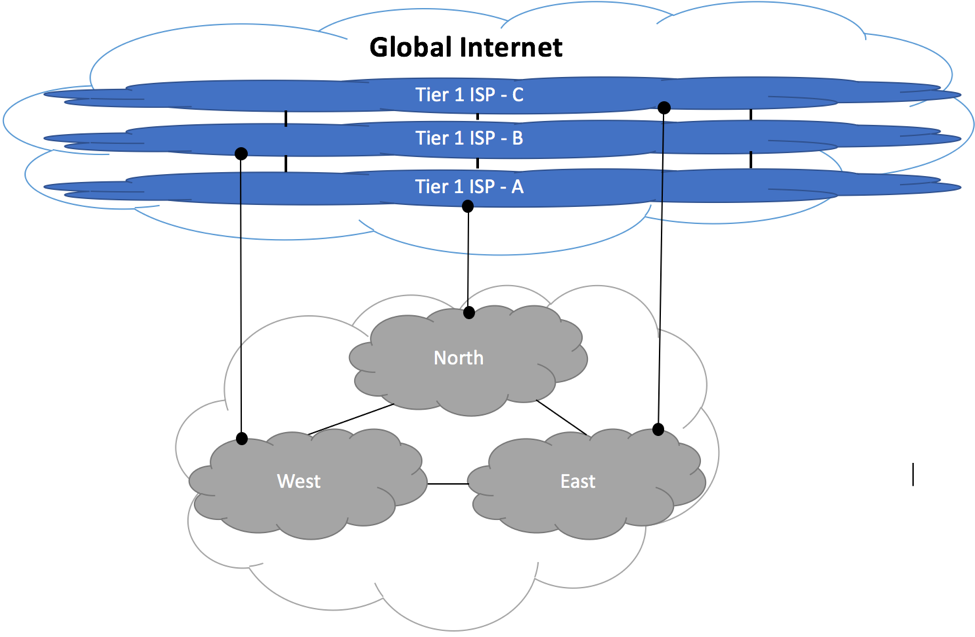
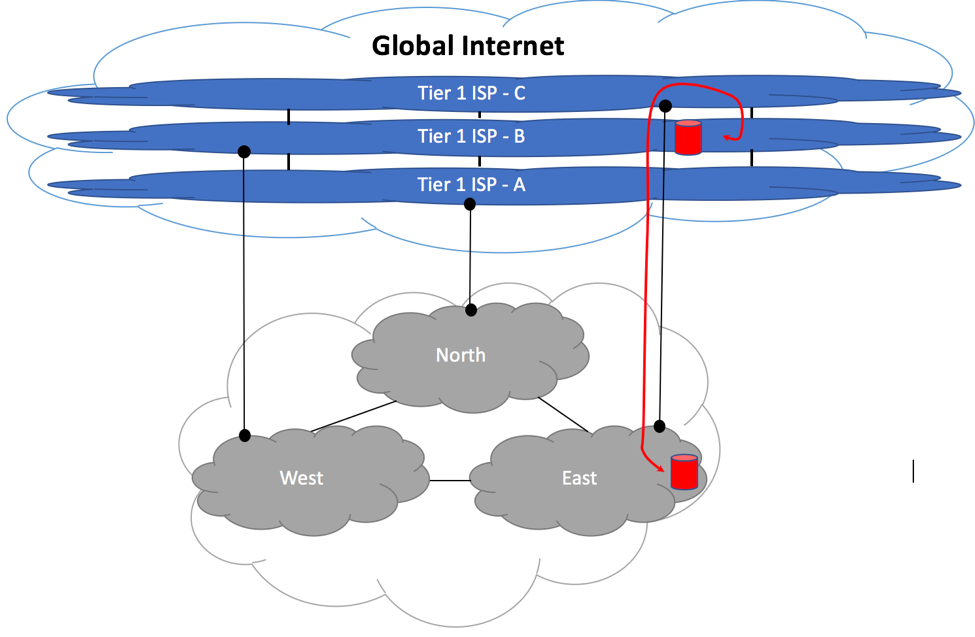
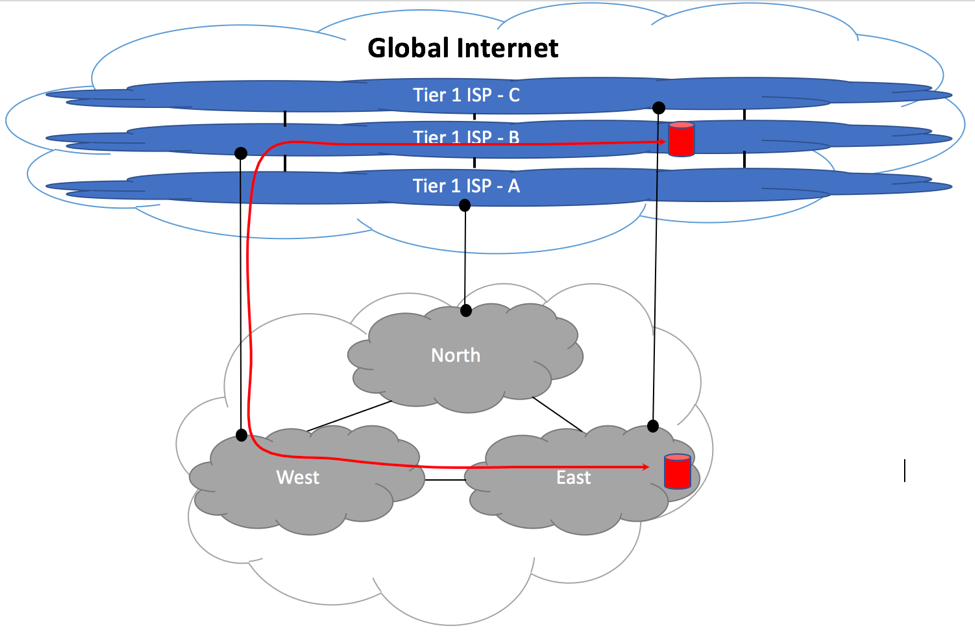
One of the most common tasks performed by BGP administrator is troubleshooting of prefix propagation over the Internet. You might have originated a prefix advertisement from within your Autonomous System, but was this prefix accepted by your Upstream Peers? If it was, did your Transit peers propagate this information to the global Internet, or did the prefix get lost or summarized somewhere within their networks because you might set a wrong community? Is it possible that your prefix has been hijacked by somebody else?
Public Looks Glass (LG) and Router-Servers (RS) allow you to get an answer to these questions in a matter of seconds. Continue reading “BGP Looking Glass”
As a BGP admin, you will often need to make decisions on the ways to partition your IP Space, which routes to advertise to the Internet and which routes to suppress.
Ideally, you’d want to aggregate your IPv4/IPv6 Space as much as possible, by only advertising aggregate prefixes (also known as supernets and summary routes) to the Internet. Practically, this would mean that your Autonomous System (AS) will originate IP prefixes assigned to you by Regional Internet Registries (RIRs) or delegated to you by Upstream Providers, while suppressing all other advertisements. If everybody were to follow this rule, the Internet routing table would be much smaller and we would not have issues with FIB exhaustion. Continue reading “Advertising Aggregates Routes”
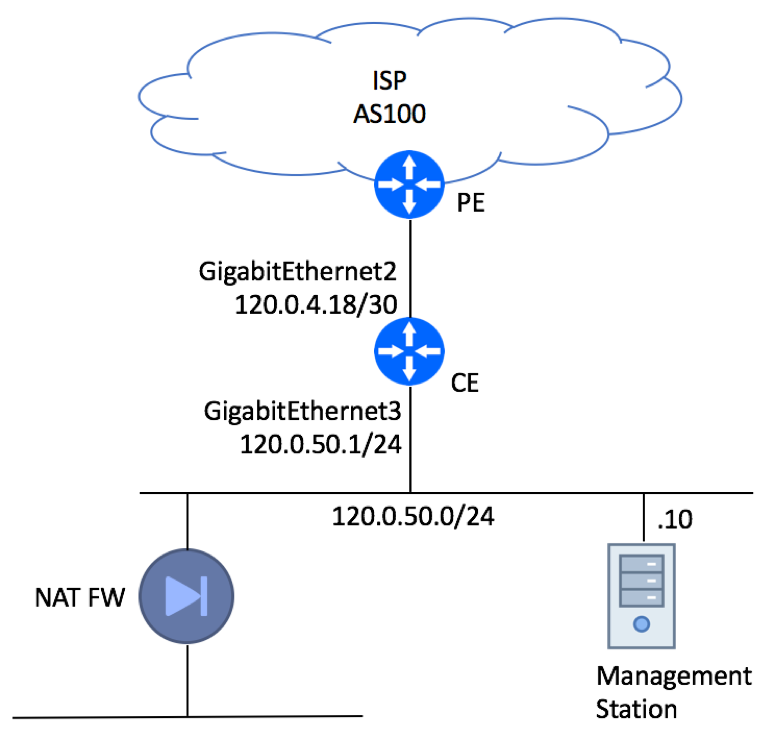
In this example, we will show recommended configuration for a Single-homed Single CE device using private AS with an upstream ISP. It is assumed that management of this device will be performed from a dedicated server residing within Customer’s Network.
This type of setup is quite common in an environment where a dedicated firewall performing source NAT function is setup to protect customer infrastructure.
Cisco Single Homed CE
Please note, that the Management Station is connected directly to the LAN interface for illustration purpose only. In real production deployments, Management Station must be protected by a firewall.
BGP Configuration
BGP configuration can be split in the following tasks:
Accept the default route from the ISP while discarding all other advertisements that might be sent to your CE
Advertise your subnet (120.0.50.0/24) while making sure that no other routers are erroneously injected
Secure BGP session by configuring a MD5 key
The actual configuration is comprised of the following blocks:
Configure Two prefix lists – one with the subnet you’ll advertise upstream and the other one with the default route you’ll be receiving from your ISP:
Next step is to secure the router itself. But default, it will pass any traffic (with some exceptions, not covered in this article) and accept connections from anywhere on the Internet. Your job is to make sure that only trusted sources can communicate with your device (control plane protection) and spoofed traffic is not allowed in and out of your network (data plane protection).
Data Plane Protection
Configure access-list to block spoofed traffic originated on the Internet:
ip access-list extended martians deny ip host 255.255.255.255 any deny ip 0.0.0.0 0.255.255.255 any deny ip 127.0.0.0 0.255.255.255 any deny ip 10.0.0.0 0.255.255.255 any deny ip 172.16.0.0 0.15.255.255 any deny ip 192.168.0.0 0.0.255.255 any deny ip 196.18.0.0 10.1.255.255 any deny ip 240.0.0.0 15.255.255.255 any deny ip 224.0.0.0 15.255.255.255 any deny ip 169.254.0.0 0.0.255.255 any deny ip 192.0.0.0 0.255.255.255 any deny ip 198.0.0.0 0.255.255.255 any deny ip 203.0.0.0 0.255.255.255 any deny ip 100.64.0.0 0.0.63.255 any! ßLocal Traffic, should not be arriving from the Internet à deny ip 120.0.50.0 0.0.0.255 any permit ip any any
Configure interface with security commands and uRPF on the LAN interface. Note that ‘no ip unreachables’ will block traceroute.
interface GigabitEthernet2 description 'CE5->PE2' ip address 120.0.4.18 255.255.255.252 no ip redirects no ip unreachables no ip proxy-arp ip access-group martians in negotiation auto!interface GigabitEthernet3 description 'LAN Segment' ip address 120.0.50.1 255.255.255.0 no ip redirects no ip unreachables no ip proxy-arp ip verify unicast source reachable-via rx negotiation auto
!
Control Plane Protection
Configure Logging; Enable SSH and SNMP access-lists, disabled unnecessary services and protocols:
no ip http server
no ip http secure-server
ip route 192.168.74.0 255.255.255.0 192.168.3.18
ip ssh rsa keypair-name ssh-key
ip ssh version 2
logging host 120.0.50.10
access-list 10 permit 120.0.50.10
snmp-server community t0ps3crrr3t RO 10
line vty 0 4
access-class 10 in
exec-timeout 11 0
password d0ntt3ll
login local
transport input ssh
!
Configure Control Plane (CPP) Protection
! Routing Protocols (BGP)
access-list 120 permit tcp any gt 1024 host 120.0.4.18 eq bgpaccess-list 120 permit tcp any eq bgp host 120.0.4.18 gt 1024 established
! Management Protocols (SSH, SNMP)
access-list 121 permit tcp host 120.0.50.10 host 120.0.50.1 eq 22access-list 121 permit tcp host 120.0.50.10 eq 22 host 120.0.50.1 establishedaccess-list 121 permit udp host 120.0.50.10 host 120.0.50.1 eq snmp
! Ping / Traceroute LAN Interface
access-list 122 permit icmp any host 120.0.50.1 echoaccess-list 122 permit icmp any host 120.0.50.1 echo-replyaccess-list 122 permit icmp any host 120.0.50.1 ttl-exceededaccess-list 122 permit icmp any host 120.0.50.1 packet-too-bigaccess-list 122 permit icmp any host 120.0.50.1 port-unreachableaccess-list 122 permit icmp any host 120.0.50.1 unreachable
! Ping/Traceroute WAN Interface
access-list 122 permit icmp any host 120.0.4.18 echoaccess-list 122 permit icmp any host 120.0.4.18 echo-replyaccess-list 122 permit icmp any host 120.0.4.18 ttl-exceededaccess-list 122 permit icmp any host 120.0.4.18 packet-too-bigaccess-list 122 permit icmp any host 120.0.4.18 port-unreachableaccess-list 122 permit icmp any host 120.0.4.18 unreachable
! Undesired Traffic
access-list 123 permit icmp any any fragmentsaccess-list 123 permit udp any any fragmentsaccess-list 123 permit tcp any any fragmentsaccess-list 123 permit ip any any fragmentsaccess-list 123 permit tcp any any eq bgp rst
! All Other Traffic
access-list 124 permit tcp any anyaccess-list 124 permit udp any anyaccess-list 124 permit icmp any anyaccess-list 124 permit ip any any!
! Define Class-Maps
class-map match-all Catch-All-IP match access-group 124class-map match-all Management match access-group 121class-map match-all Normal match access-group 122class-map match-all Undesirable match access-group 123class-map match-all Routing match access-group 120!
! Configure CoPP Policy
policy-map RTR_CoPP class Undesirable police 8000 1500 1500 conform-action drop exceed-action drop class Routing police 100000 5000 5000 conform-action transmit exceed-action transmit class Management police 100000 20000 20000 conform-action transmit exceed-action drop class Normal police 50000 5000 5000 conform-action transmit exceed-action drop class Catch-All-IP police 50000 5000 5000 conform-action transmit exceed-action drop class class-default police 8000 1500 1500 conform-action transmit exceed-action drop
! Apply CoPP Policy
control-plane service-policy input RTR_CoPP!
Complete Router Configuration
service timestamps debug datetime localtime show-timezoneservice timestamps log datetime localtime show-timezoneservice password-encryption!hostname CE11!boot-start-markerboot-end-marker!!enable secret 5 $1$9Ah6$7tFkcd/bJRrHSx0grfmYA1!no aaa new-modelno ip source-routeno ip domain lookup!username cisco privilege 15 secret 5 $1$ZJAP$Hmq/nCv7qQcwPHyB4Ixdo0!!class-map match-all Catch-All-IP match access-group 124class-map match-all Management match access-group 121class-map match-all Normal match access-group 122class-map match-all Undesirable match access-group 123class-map match-all Routing match access-group 120!policy-map RTR_CoPP class Undesirable police 8000 1500 1500 conform-action drop exceed-action drop class Routing police 100000 5000 5000 conform-action transmit exceed-action transmit class Management police 100000 20000 20000 conform-action transmit exceed-action drop class Normal police 50000 5000 5000 conform-action transmit exceed-action drop class Catch-All-IP police 50000 5000 5000 conform-action transmit exceed-action drop class class-default police 8000 1500 1500 conform-action transmit exceed-action drop!!interface GigabitEthernet1 description 'Out-of-Band Management' ip address 192.168.3.231 255.255.255.0 no ip redirects no ip unreachables no ip proxy-arp negotiation auto!interface GigabitEthernet2 description 'CE5->PE2' ip address 120.0.4.18 255.255.255.252 no ip redirects no ip proxy-arp ip access-group martians in negotiation auto!interface GigabitEthernet3 description 'LAN Segment' ip address 120.0.50.1 255.255.255.0 no ip redirects no ip unreachables no ip proxy-arp ip verify unicast source reachable-via rx negotiation auto!router bgp 111100 bgp log-neighbor-changes network 120.0.50.0 mask 255.255.255.0 neighbor 120.0.4.17 remote-as 100 neighbor 120.0.4.17 description PE2 neighbor 120.0.4.17 password 7 14141B180F0B neighbor 120.0.4.17 soft-reconfiguration inbound neighbor 120.0.4.17 prefix-list default-only in neighbor 120.0.4.17 prefix-list originated-out out!virtual-service csr_mgmt!ip forward-protocol nd!no ip http serverno ip http secure-serverip route 192.168.74.0 255.255.255.0 192.168.3.18ip ssh rsa keypair-name ssh-keyip ssh version 2!ip access-list extended martians deny ip host 255.255.255.255 any deny ip 0.0.0.0 0.255.255.255 any deny ip 127.0.0.0 0.255.255.255 any deny ip 10.0.0.0 0.255.255.255 any deny ip 172.16.0.0 0.15.255.255 any deny ip 192.168.0.0 0.0.255.255 any deny ip 196.18.0.0 10.1.255.255 any deny ip 240.0.0.0 15.255.255.255 any deny ip 224.0.0.0 15.255.255.255 any deny ip 169.254.0.0 0.0.255.255 any deny ip 192.0.0.0 0.255.255.255 any deny ip 198.0.0.0 0.255.255.255 any deny ip 203.0.0.0 0.255.255.255 any deny ip 100.64.0.0 0.0.63.255 any deny ip 120.0.50.0 0.0.0.255 any permit ip any any!!ip prefix-list default-only seq 10 permit 0.0.0.0/0!ip prefix-list originated-out seq 10 permit 120.0.50.0/24logging host 120.0.50.10access-list 10 permit 120.0.50.10access-list 10 permit 192.168.0.0 0.0.255.255access-list 120 permit tcp any gt 1024 host 120.0.4.18 eq bgpaccess-list 120 permit tcp any eq bgp host 120.0.4.18 gt 1024 establishedaccess-list 121 permit tcp host 120.0.50.10 host 120.0.50.1 eq 22access-list 121 permit tcp host 120.0.50.10 eq 22 host 120.0.50.1 establishedaccess-list 121 permit udp host 120.0.50.10 host 120.0.50.1 eq snmpaccess-list 122 permit icmp any host 120.0.50.1 echoaccess-list 122 permit icmp any host 120.0.50.1 echo-replyaccess-list 122 permit icmp any host 120.0.50.1 ttl-exceededaccess-list 122 permit icmp any host 120.0.50.1 packet-too-bigaccess-list 122 permit icmp any host 120.0.50.1 port-unreachableaccess-list 122 permit icmp any host 120.0.50.1 unreachableaccess-list 122 permit icmp any host 120.0.4.18 echoaccess-list 122 permit icmp any host 120.0.4.18 echo-replyaccess-list 122 permit icmp any host 120.0.4.18 ttl-exceededaccess-list 122 permit icmp any host 120.0.4.18 packet-too-bigaccess-list 122 permit icmp any host 120.0.4.18 port-unreachableaccess-list 122 permit icmp any host 120.0.4.18 unreachableaccess-list 124 permit tcp any anyaccess-list 124 permit udp any anyaccess-list 124 permit icmp any anyaccess-list 124 permit ip any any!snmp-server community t0ps3crrr3t RO 10!!control-plane service-policy input RTR_CoPP!banner motd ^CDisconnect IMMEDIATELY if you are not an authorized user!^C!line con 0 exec-timeout 11 0 password d0ntt3ll stopbits 1line vty 0 4 access-class 10 in exec-timeout 11 0 password d0ntt3ll login local transport input ssh!!end
BGP Best Practice Recommendation documented in RFC 7454 and discussed in “BGP Best Practices or Dissecting RFC 7454” article mandates the use of inbound prefix-list filtering to discard bogus route-advertisements to and from BGP peers. It is strongly recommended that you implement aforementioned filtering if you accept the full or partial BGP view from your peers.
You do not need to maintain inbound bogus route filtering if the only route you are planning to accept from your service providers is the default 0.0.0.0/0 prefix. In this scenario, you should configure an explicit prefix-filter permitting 0.0.0.0/0 route and rejecting all other advertisements.
Bogons, Martians, Bogus Advertisements
Over the years, networking professions have used various terms to refer to the same thing. These “bad” advertisements might be referred to as Bogons, Martian Lists, Bogus Advertisements, etc.
The current list is comprised of IP Blocks that are used for some kind of special use, such as RFC1918 space, Loopback block, etc. Sometime ago this list also included valid IPv4 prefixes that have not been allocated by The Internet Assigned Numbers Authority (IANA). IPv4 Space Exhaustion put stop to this. For the majority of ISPs and Enterprises, it is no longer feasible to include remaining unallocated blocks to the Bogons least, as this IPv4 space is small and constantly changing. The situation is very different when it comes to IPv6 space, and it will be discussed in IPv6 Martians article.
Importance of Bogons
The main reason for filtering-out Bogon advertisements is the Internet security. Bad things might begin to happen if you allow Bogon blocks to be accepted into your BGP domain. Let’s consider a few scenarios where hackers were able to advertise RFC1918 block to your network.
Firewall filters might consider RFC1918 blocks “trusted” space and permit dataflows that otherwise would be rejected
Spammers might send out email messages from servers in RFC1918 space, making it nearly impossible to track them back
Similar to Spam, DDoS Attacks from RFC1918 space are impossible to track
Your network might attract large volume of bogus traffic destined to RFC1918 space, such as portscans, vulnerability scans, etc
ip prefix-list martians seq 10 deny 0.0.0.0/8 le 32
ip prefix-list martians seq 20 deny 10.0.0.0/8 le 32
ip prefix-list martians seq 30 deny 100.64.0.0/10 le 32
ip prefix-list martians seq 40 deny 127.0.0.0/8 le 32
ip prefix-list martians seq 50 deny 169.254.0.0/16 le 32
ip prefix-list martians seq 60 deny 172.16.0.0/12 le 32
ip prefix-list martians seq 70 deny 192.0.0.0/24 le 32
ip prefix-list martians seq 80 deny 192.0.2.0/24 le 32
ip prefix-list martians seq 90 deny 192.168.0.0/16 le 32
ip prefix-list martians seq 100 deny 198.18.0.0/15 le 32
ip prefix-list martians seq 110 deny 198.51.100.0/24 le 32
ip prefix-list martians seq 120 deny 203.0.113.0/24 le 32
ip prefix-list martians seq 130 deny 224.0.0.0/3 le 32
ip prefix-list martians seq 9999 permit 0.0.0.0/0 le 32
router bgp 111100
...
neighbor 120.0.4.17 prefix-list martians in
Juniper Configuration
Set Format:
set policy-options policy-statement martians-ipv4 from route-filter 0.0.0.0/8 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 10.0.0.0/8 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 100.64.0.0/10 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 127.0.0.0/8 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 169.254.0.0/16 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 172.16.0.0/12 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 192.0.0.0/24 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 192.0.2.0/24 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 192.168.0.0/16 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 198.18.0.0/15 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 198.51.100.0/24 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 203.0.113.0/24 orlonger rejectset policy-options policy-statement martians-ipv4 from route-filter 224.0.0.0/3 orlonger rejectset policy-options policy-statement martians-ipv4 then acceptset protocols bgp group ebgp import martians-ipv4
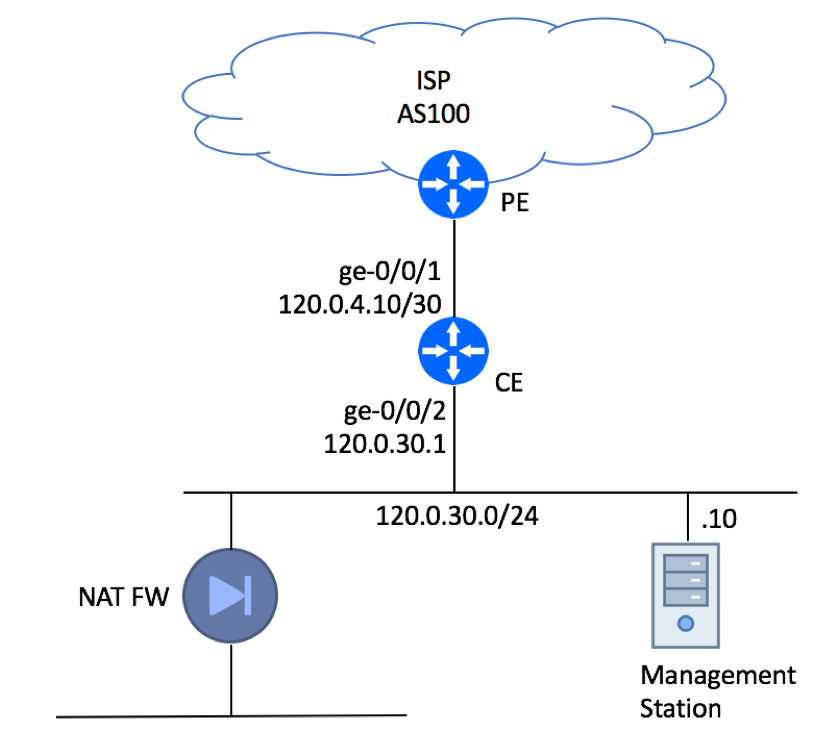
In this example, we will show recommended configuration for a Single-homed Single CE device using private AS with an upstream ISP. It is assumed that management of this device will be performed from a dedicated server residing within Customer’s Network.
This type of setup is quite common in an environment where a dedicated firewall performing source NAT function is setup to protect customer infrastructure.
Single-homed CE Device with EBGP.
Please note, that the Management Station is connected directly to the LAN interface for illustration purpose only. In real production deployments it must be protected by a firewall.
BGP Configuration
BGP configuration can be split in the following tasks:
Accept the default route from the ISP while discarding all other advertisements that might be sent to your CE
Advertise your subnet (120.0.30.0/24) while making sure that no other routers are erroneously injected
Secure BGP session by configuring a MD5 key
The actual configuration is comprised of the following blocks:
Configure Local AS Number:
set routing-options autonomous-system 65001
Configure Two prefix lists – one with the subnet you’ll advertise upstream and the other one with the default route you’ll be receiving from your ISP:
set policy-options prefix-list LocallyOriginated 120.0.30.0/24set policy-options prefix-list Default 0.0.0.0/0
Create Policy Statements for the locally originated and default route:
set policy-options policy-statement Direct-To-BGP term 10 from protocol directset policy-options policy-statement Direct-To-BGP term 10 from prefix-list LocallyOriginatedset policy-options policy-statement Direct-To-BGP term 10 then acceptset policy-options policy-statement Direct-To-BGP term 999 then rejectset policy-options policy-statement Default term 10 from prefix-list Defaultset policy-options policy-statement Default term 10 then acceptset policy-options policy-statement Default term 999 then reject
Configure BGP Group for your Upstream ISP. Configure the “export” statement to advertise your 120.0.30.0/24 subnet to the Internet and “import” statement to receive the default route. Configure MD5 Authentication Key. Make sure the description field includes the Circuit ID assigned to your link and ISP’s contact phone so you would not need to search for this information in an event of an outage.
set protocols bgp log-updownset protocols bgp group ISP-AS100 type externalset protocols bgp group ISP-AS100 import Defaultset protocols bgp group ISP-AS100 authentication-key "$9$9UPDt0IylMNdsEcds24DjCtu"set protocols bgp group ISP-AS100 export Direct-To-BGPset protocols bgp group ISP-AS100 peer-as 100set protocols bgp group ISP-AS100 neighbor 120.0.4.9 description "ISP FastAccess: Circuit GD8AJ12B: ISP NOC 800-111-2222"
Securing the Router
Next step is to secure the router itself. But default, it will pass any traffic (with some exceptions, not covered in this article) and accept connections from anywhere on the Internet. Your job is to make sure that only trusted sources can communicate with your device (control plane protection) and spoofed traffic is not allowed in and out of your network (data plane protection).
Data Plane Protection
We’ll start with the data plane, where we need to take care of packets leaving your network and packets coming in.
In our example, we were assigned a single IP subnet to be used within our network – 120.0.30.0/24. As such, we should only allow traffic originated from this network as well our ISP-facing WAN interface to go out. There are a few ways to achieve this goal – configure uRFP on LAN interface, inbound firewall filter on LAN, or outbound filter on WAN. We’ll use the latter approach by setting up outbound WAN filter:
set firewall family inet filter accept-local term 10 from source-address 120.0.30.0/24set firewall family inet filter accept-local term 10 then acceptset firewall family inet filter accept-local term 20 from source-address 120.0.4.10/32set firewall family inet filter accept-local term 20 then acceptset firewall family inet filter discard-any term 10 then discardset interfaces ge-0/0/1 unit 0 family inet filter output-list accept-localset interfaces ge-0/0/1 unit 0 family inet filter output-list discard-any
We also need to make sure that the traffic coming from the Internet has a valid source IP. As we do not receive the full BGP feed from our upstream provider and cannot rely on uRPF, we will need to configure static filter that will discard all known “bad” sources also known as Martian blocks, while allowing all other traffic in:
set firewall family inet filter discard-martian term rfc919 from source-address 255.255.255.255/32set firewall family inet filter discard-martian term rfc919 then discardset firewall family inet filter discard-martian term rfc1122 from source-address 0.0.0.0/8set firewall family inet filter discard-martian term rfc1122 from source-address 127.0.0.0/8set firewall family inet filter discard-martian term rfc1122 from source-address 240.0.0.0/4set firewall family inet filter discard-martian term rfc1122 then discardset firewall family inet filter discard-martian term rfc1918 from source-address 10.0.0.0/8set firewall family inet filter discard-martian term rfc1918 from source-address 172.16.0.0/12set firewall family inet filter discard-martian term rfc1918 from source-address 192.168.0.0/16set firewall family inet filter discard-martian term rfc1918 then discardset firewall family inet filter discard-martian term rfc2544 from source-address 198.18.0.0/15set firewall family inet filter discard-martian term rfc2544 then discardset firewall family inet filter discard-martian term rfc3171 from source-address 224.0.0.0/4set firewall family inet filter discard-martian term rfc3171 then discardset firewall family inet filter discard-martian term rfc3927 from source-address 169.254.0.0/16set firewall family inet filter discard-martian term rfc3927 then discardset firewall family inet filter discard-martian term rfc5736 from source-address 192.0.0.0/24set firewall family inet filter discard-martian term rfc5736 then discardset firewall family inet filter discard-martian term rfc5737 from source-address 192.0.2.0/24set firewall family inet filter discard-martian term rfc5737 from source-address 198.51.100.0/24set firewall family inet filter discard-martian term rfc5737 from source-address 203.0.113.0/24set firewall family inet filter discard-martian term rfc5737 then discardset firewall family inet filter discard-martian term rfc6598 from source-address 100.64.0.0/10set firewall family inet filter discard-martian term rfc6598 then discardset firewall family inet filter accept-any term 10 then acceptset interfaces ge-0/0/1 unit 0 family inet filter input-list discard-martianset interfaces ge-0/0/1 unit 0 family inet filter input-list discard-localset interfaces ge-0/0/1 unit 0 family inet filter input-list accept-any
Control Plane Protection
While it is important to discard malicious traffic that tries to pass through your router, it is even more important to drop bad packets destined to your infrastructure device. All router-bound traffic must be dropped unless it comes from a known and trusted source. In our example, we can trust ISP’s PE router as we’ll be establishing EBGP session with that device and dedicated server (120.0.30.10) used for device management. We will also allow Ping and Traceroute packets. Everything else will be dropped.
set firewall family inet filter accept-protocols term bgp from source-address 120.0.4.9/32set firewall family inet filter accept-protocols term bgp from protocol tcpset firewall family inet filter accept-protocols term bgp from port bgpset firewall family inet filter accept-protocols term bgp then acceptset firewall family inet filter accept-management term ssh from source-address 120.0.30.10/32set firewall family inet filter accept-management term ssh from source-address 192.168.3.0/24set firewall family inet filter accept-management term ssh from protocol tcpset firewall family inet filter accept-management term ssh from destination-port sshset firewall family inet filter accept-management term ssh then acceptset firewall family inet filter accept-management term snmp from source-address 120.0.30.10/32set firewall family inet filter accept-management term snmp from protocol udpset firewall family inet filter accept-management term snmp from destination-port snmpset firewall family inet filter accept-management term snmp then acceptset firewall family inet filter accept-management term ntp from source-address 120.0.30.10/32set firewall family inet filter accept-management term ntp from protocol udpset firewall family inet filter accept-management term ntp from port ntpset firewall family inet filter accept-management term ntp then acceptset firewall family inet filter accept-management term dns from source-address 120.0.30.10/32set firewall family inet filter accept-management term dns from protocol udpset firewall family inet filter accept-management term dns from protocol tcpset firewall family inet filter accept-management term dns from source-port 53set firewall family inet filter accept-management term dns then acceptset firewall family inet filter accept-monitoring term icmp from protocol icmpset firewall family inet filter accept-monitoring term icmp from icmp-type echo-replyset firewall family inet filter accept-monitoring term icmp from icmp-type echo-requestset firewall family inet filter accept-monitoring term icmp from icmp-type time-exceededset firewall family inet filter accept-monitoring term icmp from icmp-type unreachableset firewall family inet filter accept-monitoring term icmp from icmp-type parameter-problemset firewall family inet filter accept-monitoring term icmp then acceptset firewall family inet filter accept-monitoring term traceroute-udp from protocol udpset firewall family inet filter accept-monitoring term traceroute-udp from destination-port 33435-33450set firewall family inet filter accept-monitoring term traceroute-udp then acceptset firewall family inet filter discard-any term 10 then discard
These filters will be applied to Lo0 interface (Juniper’s Control plane interface).
set interfaces lo0 unit 0 family inet filter input-list accept-protocolsset interfaces lo0 unit 0 family inet filter input-list accept-managementset interfaces lo0 unit 0 family inet filter input-list accept-monitoringset interfaces lo0 unit 0 family inet filter input-list discard-any
Complete Router Configuration
Configuration in Set Format:
set system host-name CE3-Downstream3set system domain-name bgphelp.comset system time-zone America/New_Yorkset system no-redirectsset system root-authentication encrypted-password "abc"set system name-server 120.0.30.10set system login user bgphelp uid 2000set system login user bgphelp class super-userset system login user bgphelp authentication encrypted-password "abc"set system services ssh root-login denyset system services ssh protocol-version v2set system syslog user * any emergencyset system syslog host 120.0.30.10 any infoset system syslog file messages any anyset system syslog file messages authorization infoset system syslog file interactive-commands interactive-commands anyset system ntp server 120.0.30.10set interfaces ge-0/0/1 description "'CE3->PE2'"set interfaces ge-0/0/1 unit 0 family inet filter input-list discard-martianset interfaces ge-0/0/1 unit 0 family inet filter input-list discard-localset interfaces ge-0/0/1 unit 0 family inet filter input-list accept-anyset interfaces ge-0/0/1 unit 0 family inet filter output-list accept-localset interfaces ge-0/0/1 unit 0 family inet filter output-list discard-anyset interfaces ge-0/0/1 unit 0 family inet address 120.0.4.10/30set interfaces ge-0/0/2 description "LAN Segment"set interfaces ge-0/0/2 unit 0 family inet address 120.0.30.1/24set interfaces lo0 unit 0 family inet filter input-list accept-protocolsset interfaces lo0 unit 0 family inet filter input-list accept-managementset interfaces lo0 unit 0 family inet filter input-list accept-monitoringset interfaces lo0 unit 0 family inet filter input-list discard-anyset snmp location MarsDC:BAY12334:U123set snmp contact "IP NOC 1-345-12-1234"set snmp community f0ryoureyesonly clients 120.0.30.10/32set snmp trap-group all version v2set snmp trap-group all targets 120.0.30.10set routing-options autonomous-system 65001set protocols bgp log-updownset protocols bgp group ISP-AS100 type externalset protocols bgp group ISP-AS100 import Defaultset protocols bgp group ISP-AS100 authentication-key "$9$9UPDt0IylMNdsEcds24DjCtu"set protocols bgp group ISP-AS100 export Direct-To-BGPset protocols bgp group ISP-AS100 peer-as 100set protocols bgp group ISP-AS100 neighbor 120.0.4.9 description "ISP FastAccess: Circuit GD8AJ12B: ISP NOC 800-111-2222"set policy-options prefix-list LocallyOriginated 120.0.30.0/24set policy-options prefix-list Default 0.0.0.0/0set policy-options policy-statement Default term 10 from prefix-list Defaultset policy-options policy-statement Default term 10 then acceptset policy-options policy-statement Default term 999 then rejectset policy-options policy-statement Direct-To-BGP term 10 from protocol directset policy-options policy-statement Direct-To-BGP term 10 from prefix-list LocallyOriginatedset policy-options policy-statement Direct-To-BGP term 10 then acceptset policy-options policy-statement Direct-To-BGP term 999 then rejectset security forwarding-options family mpls mode packet-basedset firewall family inet filter discard-martian term rfc919 from source-address 255.255.255.255/32set firewall family inet filter discard-martian term rfc919 then discardset firewall family inet filter discard-martian term rfc1122 from source-address 0.0.0.0/8set firewall family inet filter discard-martian term rfc1122 from source-address 127.0.0.0/8set firewall family inet filter discard-martian term rfc1122 from source-address 240.0.0.0/4set firewall family inet filter discard-martian term rfc1122 then discardset firewall family inet filter discard-martian term rfc1918 from source-address 10.0.0.0/8set firewall family inet filter discard-martian term rfc1918 from source-address 172.16.0.0/12set firewall family inet filter discard-martian term rfc1918 from source-address 192.168.0.0/16set firewall family inet filter discard-martian term rfc1918 then discardset firewall family inet filter discard-martian term rfc2544 from source-address 198.18.0.0/15set firewall family inet filter discard-martian term rfc2544 then discardset firewall family inet filter discard-martian term rfc3171 from source-address 224.0.0.0/4set firewall family inet filter discard-martian term rfc3171 then discardset firewall family inet filter discard-martian term rfc3927 from source-address 169.254.0.0/16set firewall family inet filter discard-martian term rfc3927 then discardset firewall family inet filter discard-martian term rfc5736 from source-address 192.0.0.0/24set firewall family inet filter discard-martian term rfc5736 then discardset firewall family inet filter discard-martian term rfc5737 from source-address 192.0.2.0/24set firewall family inet filter discard-martian term rfc5737 from source-address 198.51.100.0/24set firewall family inet filter discard-martian term rfc5737 from source-address 203.0.113.0/24set firewall family inet filter discard-martian term rfc5737 then discardset firewall family inet filter discard-martian term rfc6598 from source-address 100.64.0.0/10set firewall family inet filter discard-martian term rfc6598 then discardset firewall family inet filter discard-local term 10 from source-address 120.0.30.0/24set firewall family inet filter discard-local term 10 then discardset firewall family inet filter accept-any term 10 then acceptset firewall family inet filter accept-local term 10 from source-address 120.0.30.0/24set firewall family inet filter accept-local term 10 then acceptset firewall family inet filter accept-local term 20 from source-address 120.0.4.10/32set firewall family inet filter accept-local term 20 then acceptset firewall family inet filter discard-any term 10 then discardset firewall family inet filter accept-protocols term bgp from source-address 120.0.4.9/32set firewall family inet filter accept-protocols term bgp from protocol tcpset firewall family inet filter accept-protocols term bgp from port bgpset firewall family inet filter accept-protocols term bgp then acceptset firewall family inet filter accept-management term ssh from source-address 120.0.30.10/32set firewall family inet filter accept-management term ssh from source-address 192.168.3.0/24set firewall family inet filter accept-management term ssh from protocol tcpset firewall family inet filter accept-management term ssh from destination-port sshset firewall family inet filter accept-management term ssh then acceptset firewall family inet filter accept-management term snmp from source-address 120.0.30.10/32set firewall family inet filter accept-management term snmp from protocol udpset firewall family inet filter accept-management term snmp from destination-port snmpset firewall family inet filter accept-management term snmp then acceptset firewall family inet filter accept-management term ntp from source-address 120.0.30.10/32set firewall family inet filter accept-management term ntp from protocol udpset firewall family inet filter accept-management term ntp from port ntpset firewall family inet filter accept-management term ntp then acceptset firewall family inet filter accept-management term dns from source-address 120.0.30.10/32set firewall family inet filter accept-management term dns from protocol udpset firewall family inet filter accept-management term dns from protocol tcpset firewall family inet filter accept-management term dns from source-port 53set firewall family inet filter accept-management term dns then acceptset firewall family inet filter accept-monitoring term icmp from protocol icmpset firewall family inet filter accept-monitoring term icmp from icmp-type echo-replyset firewall family inet filter accept-monitoring term icmp from icmp-type echo-requestset firewall family inet filter accept-monitoring term icmp from icmp-type time-exceededset firewall family inet filter accept-monitoring term icmp from icmp-type unreachableset firewall family inet filter accept-monitoring term icmp from icmp-type parameter-problemset firewall family inet filter accept-monitoring term icmp then acceptset firewall family inet filter accept-monitoring term traceroute-udp from protocol udpset firewall family inet filter accept-monitoring term traceroute-udp from destination-port 33435-33450set firewall family inet filter accept-monitoring term traceroute-udp then accept
Configuration in Curly Braces Format:
system {
host-name CE3-Downstream3;
domain-name bgphelp.com;
time-zone America/New_York;
no-redirects;
root-authentication {
encrypted-password "abc"; ## SECRET-DATA
}
name-server {
120.0.30.10;
}
login {
user bgphelp {
uid 2000;
class super-user;
authentication {
encrypted-password "abc"; ## SECRET-DATA
}
}
}
services {
ssh {
protocol-version v2;
}
netconf {
ssh;
}
}
syslog {
user * {
any emergency;
}
host 120.0.30.10 {
any info;
}
file messages {
any any;
authorization info;
}
file interactive-commands {
interactive-commands any;
}
}
archival {
configuration {
transfer-on-commit;
archive-sites {
"scp://cfg:[email protected]/home/cfg/config-backups/";
}
}
}
ntp {
server 192.168.3.210;
}
}
interfaces {
ge-0/0/1 {
description "'CE3->PE2'";
unit 0 {
family inet {
filter {
input-list [ discard-martian discard-local accept-any ];
output-list [ accept-local discard-any ];
}
address 120.0.4.10/30;
}
}
}
ge-0/0/2 {
description "LAN Segment";
unit 0 {
family inet {
address 120.0.30.1/24;
}
}
}
lo0 {
unit 0 {
family inet {
filter {
input-list [ accept-protocols accept-management accept-monitoring discard-any ];
}
}
}
}
}
snmp {
location MarsDC:BAY12334:U123;
contact "IP NOC 1-345-12-1234";
community f0ryoureyesonly {
clients {
120.0.30.10/32;
}
}
trap-group all {
version v2;
targets {
120.0.30.10;
}
}
}
routing-options {
static {
route 192.168.74.0/24 {
next-hop 192.168.3.18;
no-readvertise;
}
}
autonomous-system 65001;
}
protocols {
bgp {
log-updown;
group ISP-AS100 {
type external;
import Default;
authentication-key "$9$9UPDt0IylMNdsEcds24DjCtu"; ## SECRET-DATA
export Direct-To-BGP;
peer-as 100;
neighbor 120.0.4.9 {
description "ISP FastAccess: Circuit GD8AJ12B: ISP NOC 800-111-2222";
}
}
}
}
policy-options {
prefix-list LocallyOriginated {
120.0.30.0/24;
}
prefix-list Default {
0.0.0.0/0;
}
policy-statement Default {
term 10 {
from {
prefix-list Default;
}
then accept;
}
term 999 {
then reject;
}
}
policy-statement Direct-To-BGP {
term 10 {
from {
protocol direct;
prefix-list LocallyOriginated;
}
then accept;
}
term 999 {
then reject;
}
}
}
firewall {
family inet {
filter discard-martian {
term rfc919 {
from {
source-address {
255.255.255.255/32;
}
}
then {
discard;
}
}
term rfc1122 {
from {
source-address {
0.0.0.0/8;
127.0.0.0/8;
240.0.0.0/4;
}
}
then {
discard;
}
}
term rfc1918 {
from {
source-address {
10.0.0.0/8;
172.16.0.0/12;
192.168.0.0/16;
}
}
then {
discard;
}
}
term rfc2544 {
from {
source-address {
198.18.0.0/15;
}
}
then {
discard;
}
}
term rfc3171 {
from {
source-address {
224.0.0.0/4;
}
}
then {
discard;
}
}
term rfc3927 {
from {
source-address {
169.254.0.0/16;
}
}
then {
discard;
}
}
term rfc5736 {
from {
source-address {
192.0.0.0/24;
}
}
then {
discard;
}
}
term rfc5737 {
from {
source-address {
192.0.2.0/24;
198.51.100.0/24;
203.0.113.0/24;
}
}
then {
discard;
}
}
term rfc6598 {
from {
source-address {
100.64.0.0/10;
}
}
then {
discard;
}
}
}
filter discard-local {
term 10 {
from {
source-address {
120.0.30.0/24;
}
}
then {
discard;
}
}
}
filter accept-any {
term 10 {
then accept;
}
}
filter accept-local {
/* LAN Segment */
term 10 {
from {
source-address {
120.0.30.0/24;
}
}
then accept;
}
/* Point-To-Point WAN Interface */
term 20 {
from {
source-address {
120.0.4.10/32;
}
}
then accept;
}
}
filter discard-any {
term 10 {
then {
discard;
}
}
}
filter accept-protocols {
term bgp {
from {
source-address {
120.0.4.9/32;
}
protocol tcp;
port bgp;
}
then accept;
}
}
filter accept-management {
term ssh {
from {
source-address {
120.0.30.10/32;
192.168.3.0/24;
}
protocol tcp;
port ssh;
}
then accept;
}
term snmp {
from {
source-address {
120.0.30.10/32;
}
protocol udp;
destination-port snmp;
}
then accept;
}
term ntp {
from {
source-address {
120.0.30.10/32;
}
protocol udp;
port ntp;
}
then accept;
}
term dns {
from {
source-address {
120.0.30.10/32;
}
protocol [ udp tcp ];
source-port 53;
}
then accept;
}
term netconf {
from {
source-address {
120.0.30.10/32;
192.168.3.0/24;
}
protocol tcp;
destination-port 830;
}
then accept;
}
}
filter accept-monitoring {
term icmp {
from {
protocol icmp;
icmp-type [ echo-reply echo-request time-exceeded unreachable source-quench router-advertisement parameter-problem ];
}
then accept;
}
term traceroute-udp {
from {
protocol udp;
destination-port 33435-33450;
}
then accept;
}
}
}
}
This document provides a cheat sheet of commonly used troubleshooting commands used in Cisco and Juniper environments. The list is incomplete. Please send us a note if you want to contribute.
Management
Cisco IOS
Juniper JunOS
Description
show tech-support
request support info
request support information | save /var/tmp/RSI.txt
file archive compress source RSI.txt destination RSI.txt.tgz
Gather support info for vendor’s TAC
show hardware
show chassis hardware
Show hardware-related info
show version
show system uptime
Show system’s uptime
show processes cpu
show processes cpu sorted
show processes cpu history
show chassis routing-engine
show system processes extensive
show system threads
Verify CPU Utilization
show processes memory
show memory summary
show system processes extensive
show task memory detail
Verify Memory Utilization
dir bootflash:
show system core-dumps
Check for crash files / core dumps
dir
file list
Show directory structure
show system storage
Verify available storage space
show users
show system users
List connected users
clear line X
request system logout user ABC
Disconnect user
start shell
Enter Unix Shell
monitor traffic interface ge-0/0/1
Monitor traffic on the interface (will not show transit packets)
As the name suggests, BGP-Free Core is a network deployment approach where Service Providers’ Core routers do not run BGP. This is done by employing a tunneling mechanism of some sort, most commonly MPLS.
What are the advantages of a BGP-Free Core?
There are many, to list just a few:
Core devices do not need to be capable of supporting a large number of IPv4/IPv6 routes, allowing you to deploy devices with limited RIB and FIB Capacity
As there is no BGP, Core devices will not be impacted by BGP-related issues, such as high CPU utilization during massive BGP re-convergence
By not running BGP, you eliminate one of the attack vectors – if a new BGP security vulnerability were to be discovered, Core devices would not be impacted
Operators’ mistakes associated with BGP configuration can be eradicated
New services such as MPLS VPN, IPv6, EVPN can be introduced without modifying the Core routers
If deployed properly, BGP-Free becomes unreachable from the Internet, making DDoS and hacking attacks against ISPs’ Core elements impossible
What are the disadvantages of a BGP-Free Core?
Here are some known limitations of a BGP-Free Core:
The edge of your network will be tunneling traffic over BGP-Free Core, meaning that edge devices must support some kind of a tunneling mechanism. Your current edge devices might not be able to do this, or there might be a performance penalty associated with tunneling
Increased links utilization is associated with tunnel overhead. Depending on the tunneling mechanism you chose and the average packet size on your network, you will see 1% to 5% link utilization increase associated with tunnels (4-bytes for single-label MPLS, 24-bytes for GRE)
It is expected that packets with the size of at least 1,500-bytes can be sent through a Service Provider’s network without fragmentation. You will need to increase interface MTU size on your Core-to-Core and Core-to-Edge links to accommodate tunneling header. Some L2 transport technologies might not allow you to do this
Because your core will no longer have BGP, you will not be able to connect customers directly to your core nodes. Although connecting customers to the core is a bad practice, many companies do this to save on cost
BGP-Enabled Edge is by far the most common scenario that goes hand-in-hand with BGP-Free Core. This means that your Edge devices will need to support BGP. This might not always be possible or might have a licensing cost associated with BGP features.
BGP-Free Core might lead to sub-optimal traffic flows, if not planned properly. We’ll talk about this in the next section
What might cause sub-optimal traffic flow in a BGP-free environment?
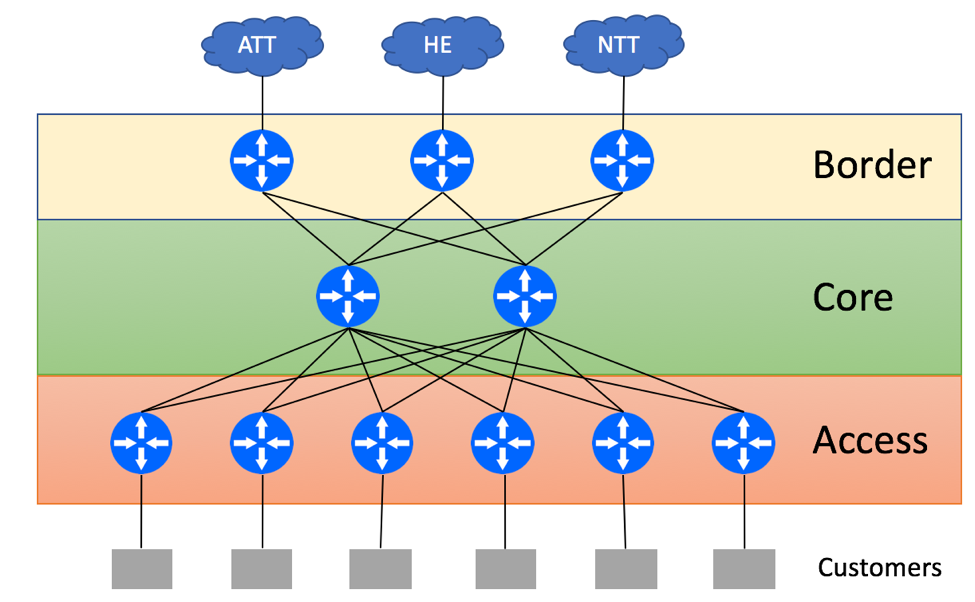
Consider the following typical Service Provider topology:
ISP Environment – Typical Topology
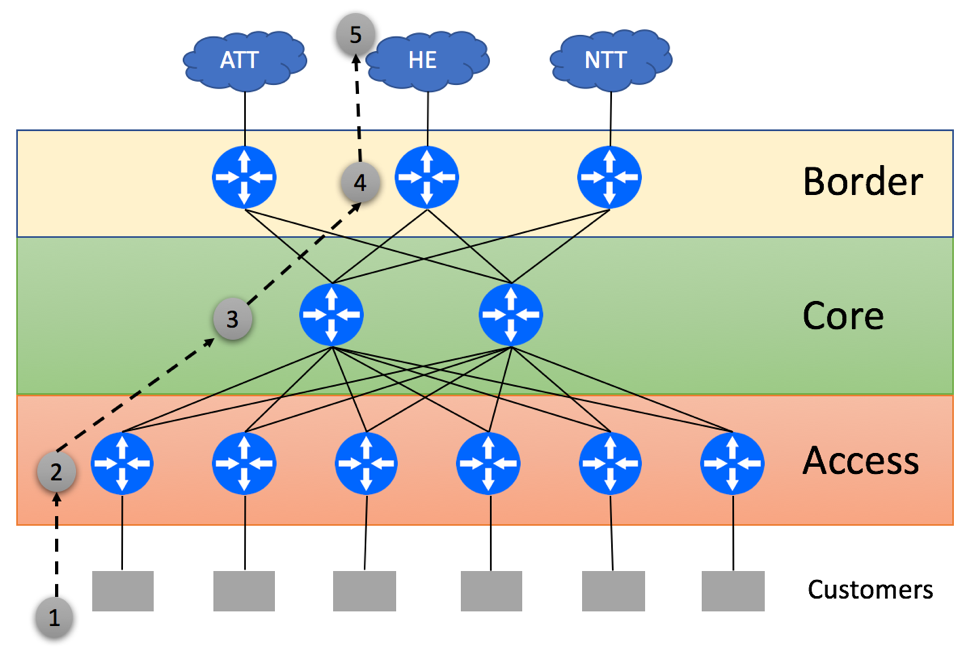
ISP has a dedicated Core Layer that aggregates connections from Border Layer devices used for external peering connectivity and Access Layer devices used for Customer connectivity. ISP is connected to three upstream providers and receives the full BGP feed from all of them. In a non-BGP-Free Core environment, Borders routers will re-advertise the routes received from external peers via IBGP to Core routers. Core routers can be used as Route-Reflectors and re-advertise full BGP view to the Access devices. If Access devices are not capable of supporting the full BGP view, you might be able to get away with advertising just the default route from the Core to Access devices. As Core routers have the full BGP view, they can find the optimal exit point for the traffic leaving the network.
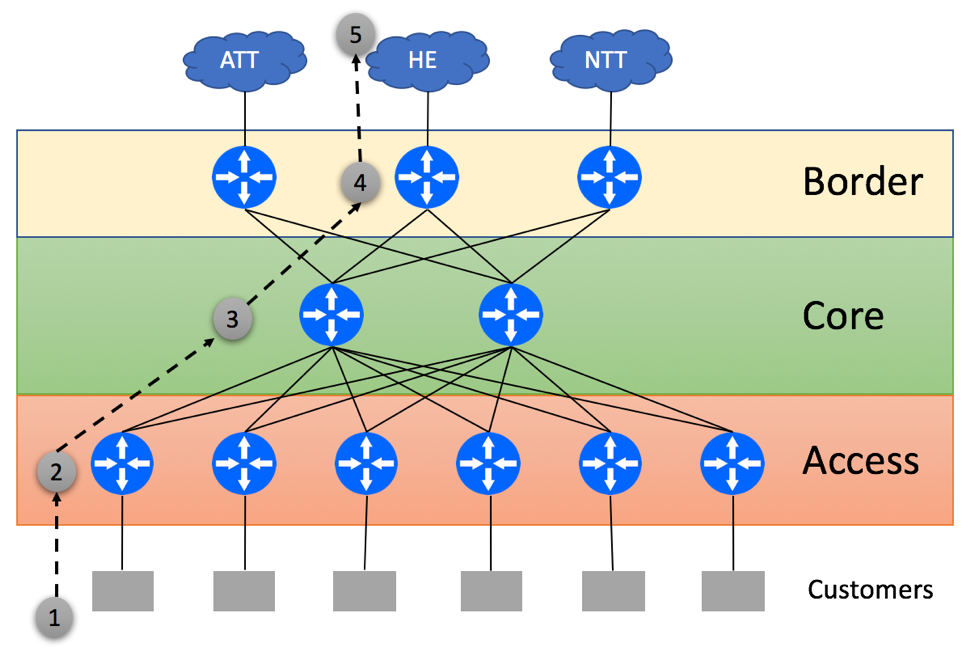
Let’s review packet flow scenario with traffic originating within ISP’s customer’s network and being destined to a prefix that resides on the HE network. In our case, ISP’s Access layer does not have the full BGP view and relies on the default route received from Core routers.
Typical Full BGP View Topology
Customer Originates the packet
Access Layer device within ISP’s network uses the default route to send packet to one of Core routers in a round-robin fashion
Core device does a lookup and determines that the destination on the HE’s network is best reachable via the middle border router
Border router forwards this packet to the HE
Server within the HE network receives the packet
Now, let’s talk about a BGP-Free Core. It is assumed that the Core has no knowledge of Customer-owned or Peer-advertised destinations and is only capable of forwarding traffic to IP destinations that belong to ISP’s internal infrastructure. Access and Border devices will have a full mesh of Tunnels (LSP’s in MPLS terminology) and will pass traffic via those tunnels.
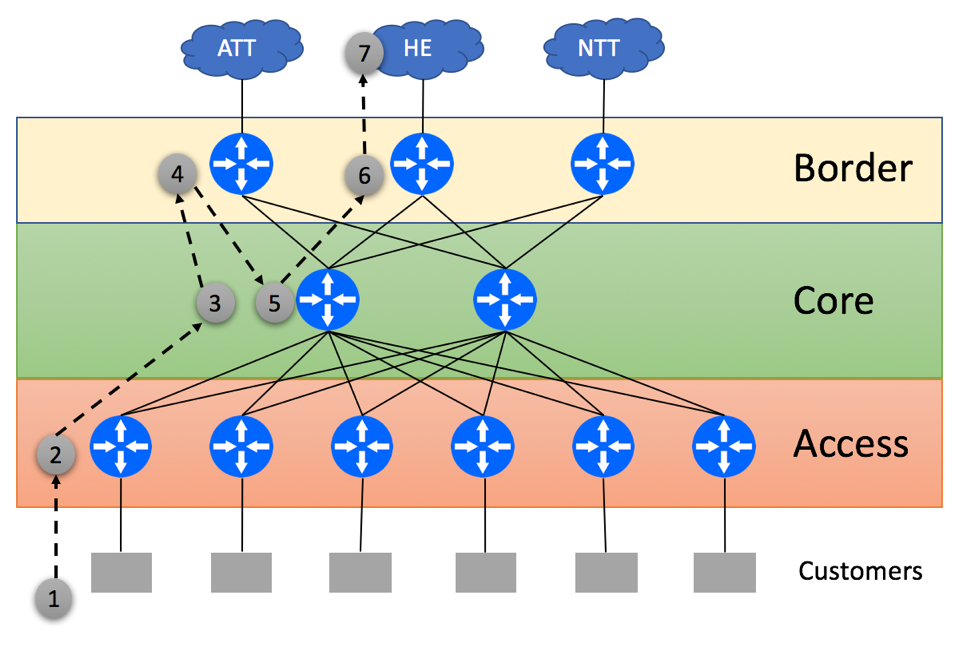
We’ll start with the scenario where Access routers have enough RIB and FIB capacity to support the full BGP view from the Border devices.
In this case, Access layer will make optimal forwarding decisions as shown below:
Optimal Routing due to Full BGP View
Customer Originates the packet
Access Layer device does a lookup in its BGP tables and determines that the Middle Border router is the best gateway to reach the HE. Access Layer device will encapsulate customer-originated traffic into a tunnel and send it to the Border via one of the Core routers
Core device receives tunneled traffic and delivers it to the intended Border router
Middle Border Router sends packet to the HE
Server within the HE network receives the packet
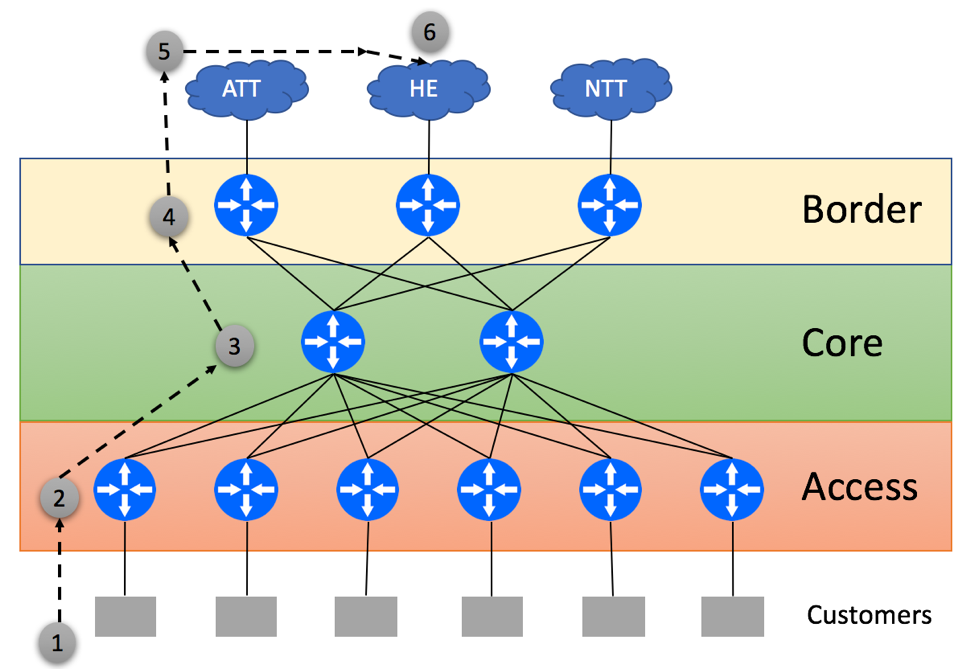
In our next scenario, Access routers are not capable of supporting the full BGP view and have to rely on the default routes, this time advertised by the Border Routers. This might lead to suboptimal traffic flow as shown below:
Suboptimal Routing due to Default-Only Routing
Customer Originates the packet
Access Layer device within ISP’s network uses the default route and tunnels packet to one of the Border routers in a round-robin fashion. It is not able to determine the best egress point, as Access device does not maintain the full BGP view
Core device tunnels the traffic to the Border device selected by the Access Layer
Left Border router does IP Destination lookup and determines that the optimal path to the prefix on the HE network is via the Middle Border. It Tunnels traffic to that Border
Core router receives a tunnel-encapsulated packet and sends it to the Middle Border
Middle Border Router sends the packet to the HE
Server within the HE network receives the packet
Another permutation of the previous scenario is shown below. This time BGP policies on the Border routers force traffic to leave via directly connected EBGP peer, even if the better path exists:
Suboptimal Routing due to BGP-Free Core and Default-Only Access
Customer Originates the packet
Access Layer device within ISP’s network uses the default route and tunnels packet to one of the Border routers in a round-robin fashion. It is not able to determine the best egress point, as Access device does not maintain the full BGP view
Core device tunnels the traffic to the Border device selected by the Access Layer
Left Border router does IP Destination lookup and selects directly connected EBGP Upstream to send the traffic
AT&T’s network delivers the packet to HE
Server within the HE network receives the packet
While both deployment scenarios allow for the traffic to be delivered to intended destinations, it is easy to spot that packets might need to traverse the additional hops. This will often lead to increased round-trip latency and unnecessary link utilization.
Conclusion
BGP-Free Core is a popular deployment mechanism that is employed by thousands of ISPs around the globe. It helps to save cost and improves operational stability of the network. With this being said, you should be aware of the deployment caveats highlighted above and be ready to address those in your network design.
In this article, we will focus on the RFC 7547. This RFC covers BGP Operations and Security best current practices and needs to be understood and implemented by any organization running BGP in production.
Introduction
RFC 7547 recommendations can be split into the following categories:
BGP Session Protection
Prefix Filtering Recommendations
AS-Path Filtering Recommendations
Next-Hop Filtering
Optional BGP Community Scrubbing
Traffic Filtering Recommendations
In this article, we will use Roman Numerals (I, II, etc) to identify BGP protection mechanisms, Arabic Numerals (1,2, etc) to identify Traffic Filtering, Uppercase Letters (A, B, etc) to identify Prefix Filtering, and Lowercase Letter (a,b, etc) to identify AS-Path filtering and Greek Letters (α, β) to identify BGP scrubbing.
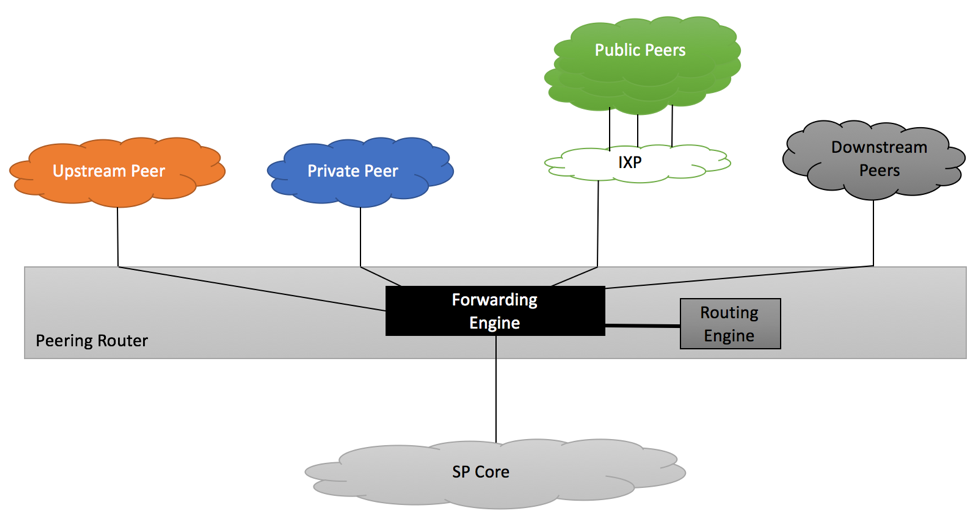
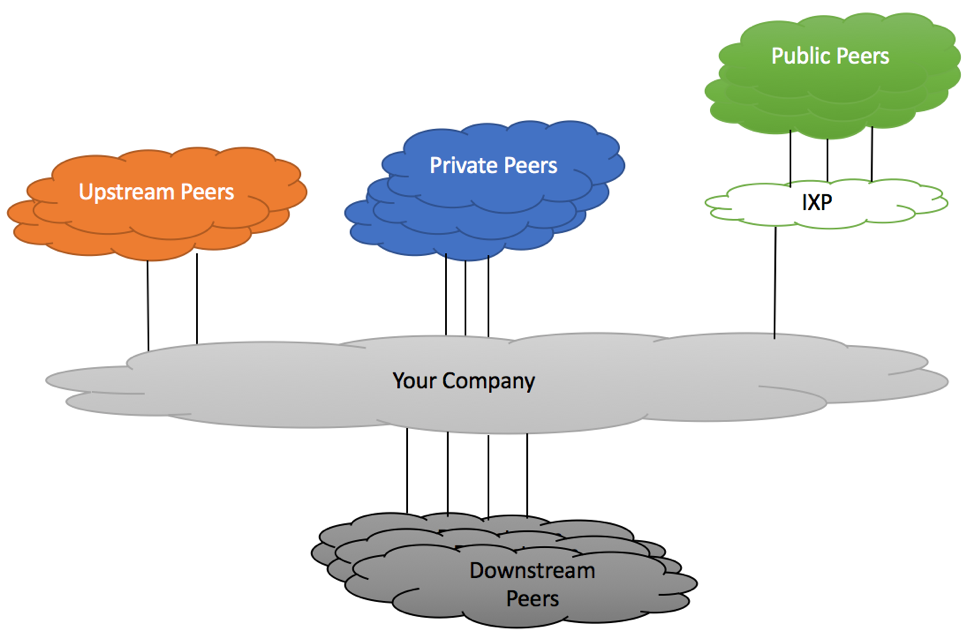
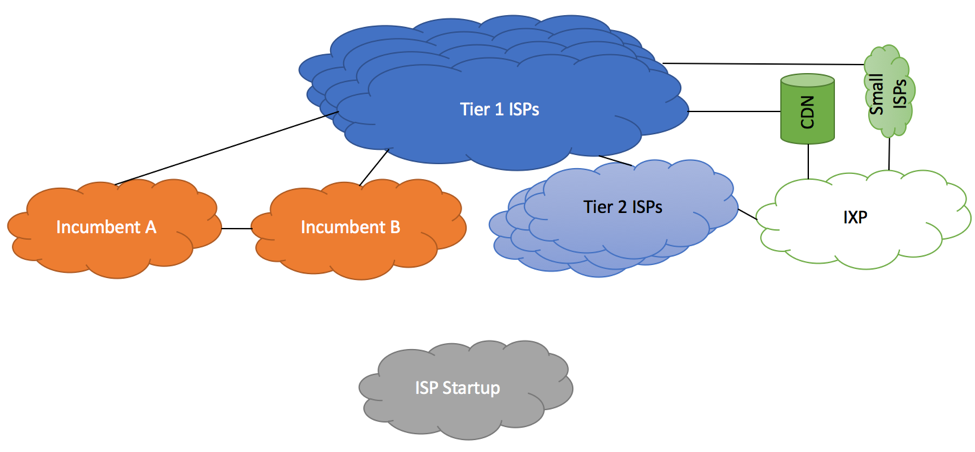
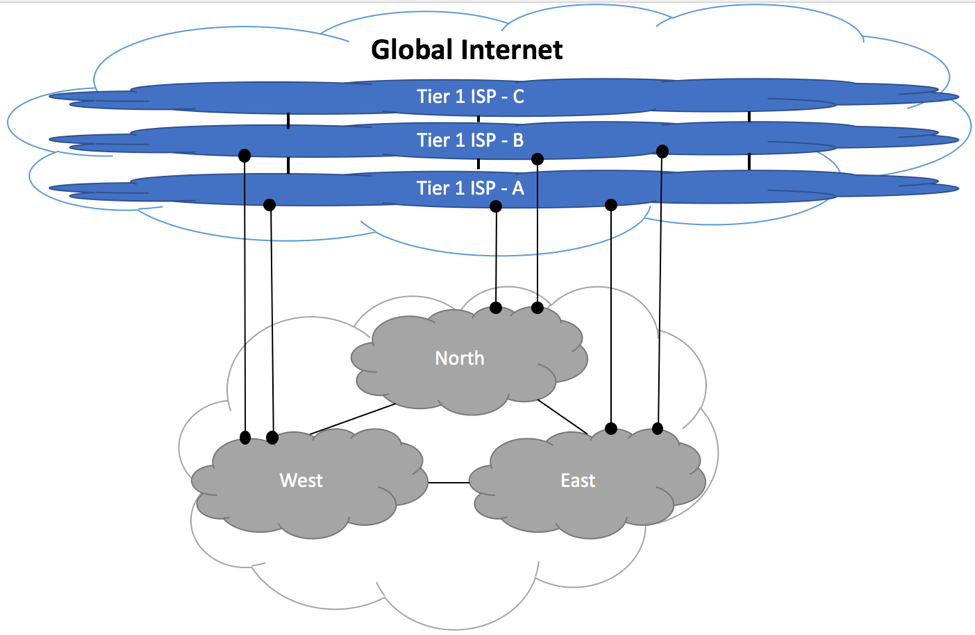
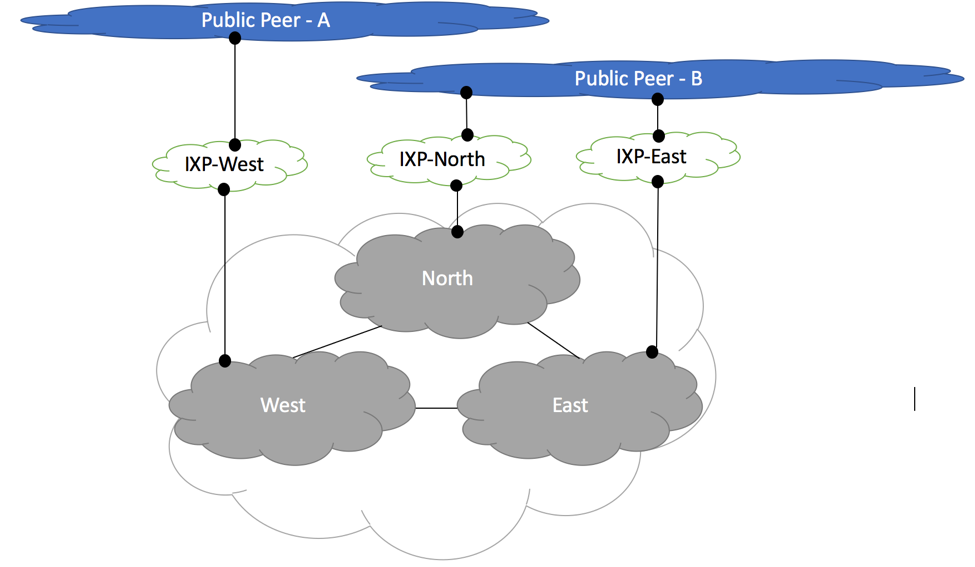
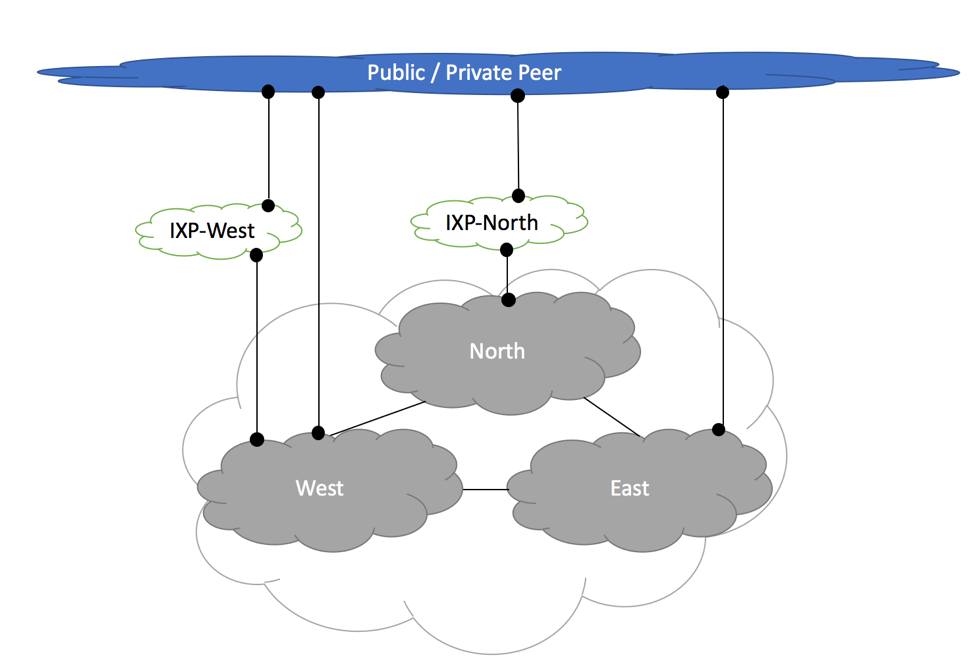
Figure below shows depicts peering routers connected to upstream, private, IXP and downstream peers.
RFC7454 Peering Router
As most of the modern routers do, our sample router has a dedicated forwarding engine responsible for forwarding packets and a dedicated routing engine responsible for participating in routing protocols, building Routing Information Base (RIB) and Forwarding Information Base (FIB) tables. While actual vendors’ implementations will vary between routers’ models, best practices discussed in this article are generic enough to be applicable to the majority of vendors.
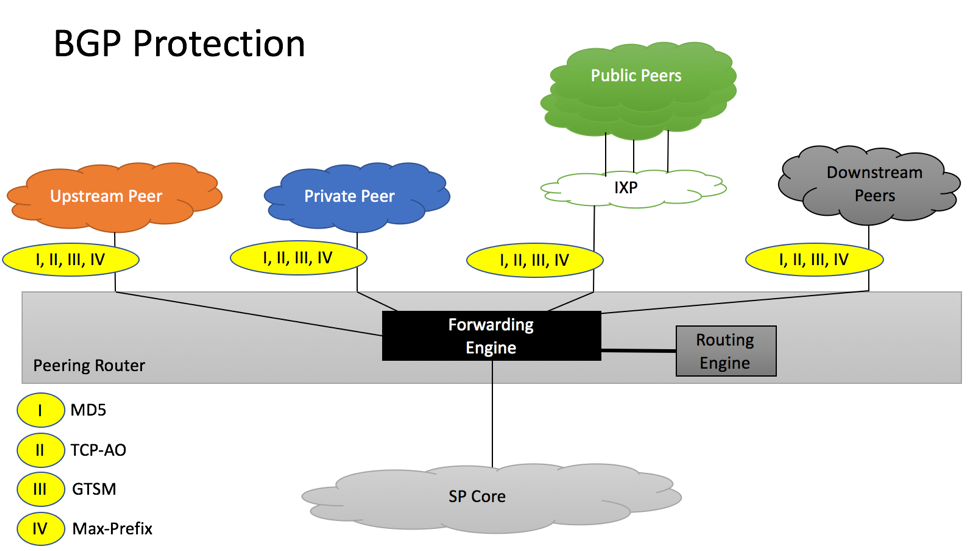
BGP Protection
Group of BGP Protection mechanisms is responsible for maintaining stability of BGP sessions, as well as providing anti-spoofing and bogus route-injection protection mechanisms. We will also add “maximum-prefix” protection mechanism to this category, as it helps to protect against operators’ mistakes.
RFC7454 BGP Protection
I. GTSM (TTL Security)
GTSM – Generalized TTL Security Mechanisms, also known as TTL security, defined in RFC 5082. GTSM (TTL Security) is a mechanism that checks TTL value of incoming IP Packets in order to make sure they have not been spoofed. Directly connected BGP peers will set IP TTL value to 255, making it impossible to deliver spoofed IP with TTL=255 packets via non-directly connected interfaces. As per section 5.2 of RFC 7454 GTSM should be implemented.
TCP-AO – TCP Authentication Option is a stronger protection mechanism than traditionally used MD5, it is described in RFC 5925. At some point, it is expected to replace MD5 for session protection. It has not been widely adopted due to the lack of implementation from equipment vendors.
Section 5.1 of RFC 7454 recommends, although does not require, leveraging either MD5 or TCP-AO for session protection.
No configuration examples due to lack of vendors’ implementation.
III. MD5
MD5 – Protection of the TCP session header, described in RFC 2385. MD5 is a TCP session protection mechanism that has been available for many years and is supported by the vast majority of equipment manufacturers. It has become the de-facto standard for BGP session protection. Although it has been made obsolete by TCP-AO protection, it is still used for the majority of BGP peering sessions.
Configuration Examples (Simple Key and Key-Chains):
Maximum-Prefix Limit is one of the commonly used safety mechanisms that will bring down BGP session if the number of routes advertised by the peer exceeds pre-configured limit. Section 8 of RFC 7454 provides the following recommendations:
From public and private peers, it is recommended to have the limit set to either a lower than the number of routes on the Internet, or to a specific number for each peer based on the advertised number of routes plus some headroom. From the author’s experience, setting the number to below the number of routes on the Internet is too risky and should be avoided. There have been situations where public and private peers would make an error and leak the entire BGP table to their peering partners, causing major network instability. Author prefers setting session reset limit to 2x the number of routes normally advertised by the peer and session warning limit to 1.5x number of routes. Your NOC should monitor logs for warning threshold violations and adjust limits accordingly.
From upstream, the number of routes should be set higher than the number of routes on the Internet, but not higher that the capabilities of your routers. For example, if FIB tables of your devices can support up to 1 Million IPv4 routes, you can set the limit to be 950,000 routes. While resetting BGP sessions with your upstream providers is never a good thing, damage caused by reset is much lower than that caused by FIB exhaustion. For more information, please refer to our article on BGP Table Size analysis (http://www.bgphelp.com/2017/01/01/bgpsize/).
MD5, TCP-AO and GTSM have to be configured on both sides of the BGP session. Max-Prefix can be configured on one side only.
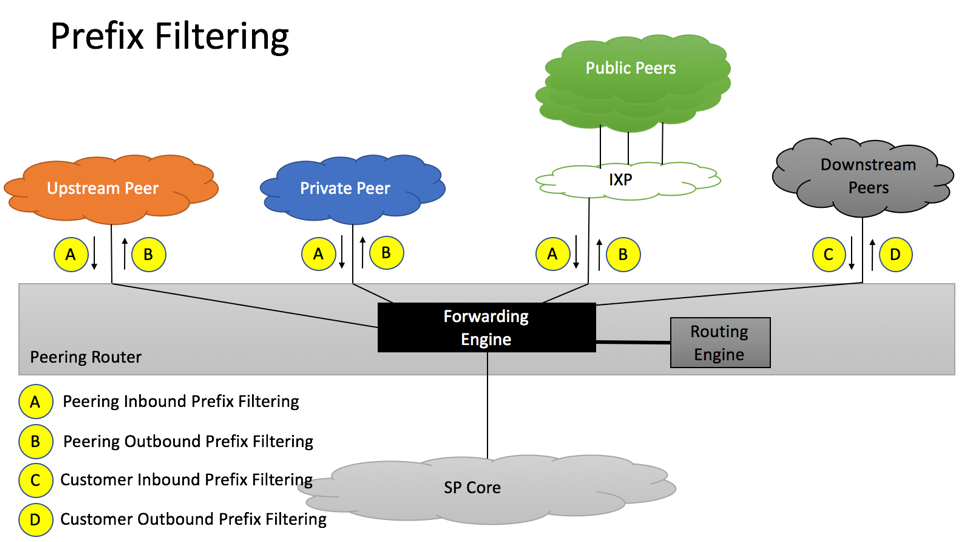
Prefix Filtering
Prefix-filtering policies are responsible for discarding bogus route-advertisements to and from BGP peers. Examples of these bogus advertisements are prefixes from RFC1918 address space, to specific routes (>24), unallocated prefixes.
RFC7454 Prefix Filtering
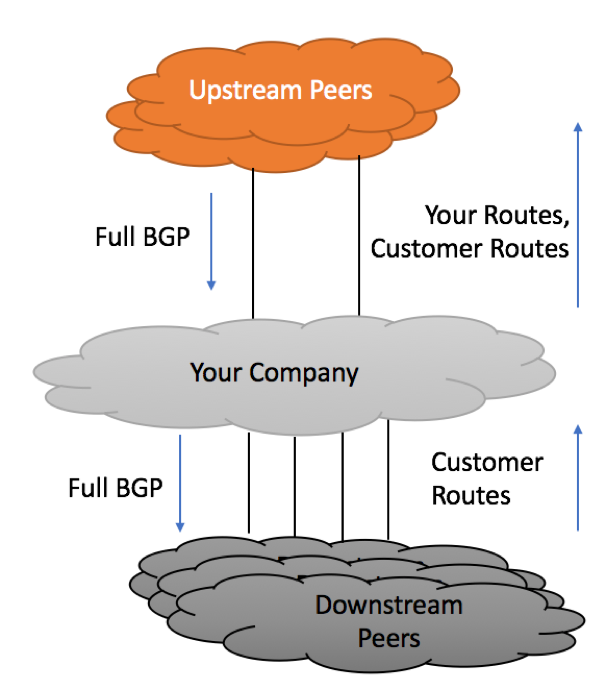
Route-filtering should be implemented on each BGP session maintained by the service provider:
A. Private/Public/Transit Inbound Prefix Filtering
B. Private/Public/Transit Outbound Prefix Filtering
C. Downstream Inbound Prefix Filtering
D. Downstream Outbound Prefix Filtering
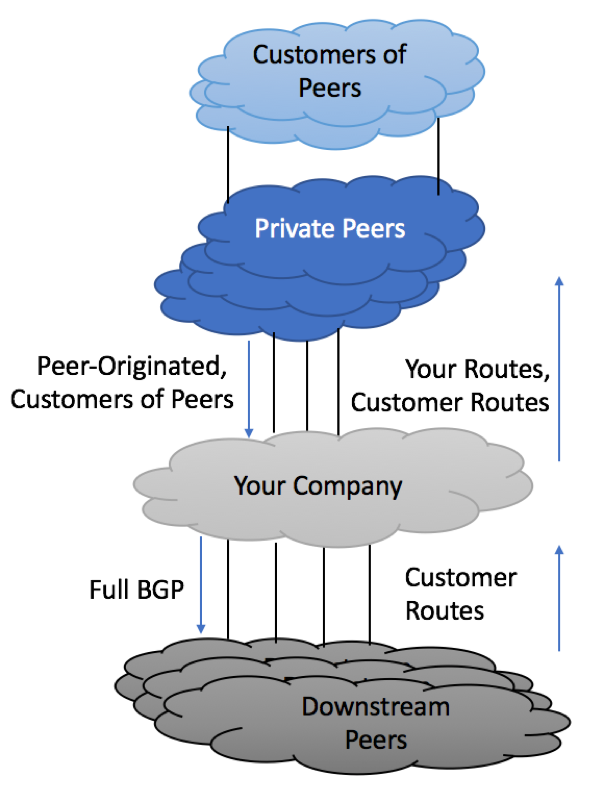
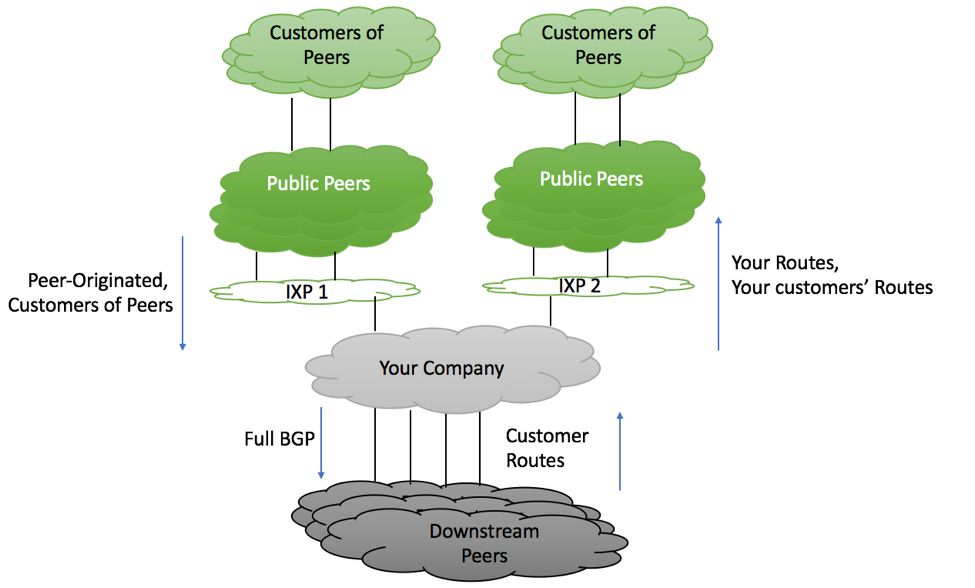
A. Inbound Prefix Filtering from Private/Public/Transit Peers
RFC 7475 provides similar recommendations for route filtering from Upstream Providers (section 6.2.3) and route-filtering from private and public peers (section 6.2.1). Because of this, there is very little difference in filtering policies, allowing us to combine them in one recommendation.
As per Section 6.2.1.1.1 of RFC 7475, the following prefixes should not be accepted from peers
Special-Purpose Prefixes (RFC 7475 Section 6.1.1)
Unallocated Prefixes (RFC 7475 Section 6.1.2)
Prefixes that are too specific (RFC 7475 Section 6.1.3)
Prefixes belonging to the local AS (RFC 7475 Section 6.1.4)
IXP LAN Prefixes (RFC 7475 Section 6.1.5), other than authorized ASes (RFC 7475 Section 6.1.5)
The Default Route (RFC 7475 Section 6.1.6)
Section 6.2.1.1.2 of RFC 7475 also provides recommendations for “Strict” inbound filtering option, which we consider to be too risky and will not cover in this document.
B. Outbound Prefix Filtering towards Private/Public/Transit Peers
As per Section 6.2.1.2 of RFC 7475, the following prefixes should not be accepted from peers
Special-Purpose Prefixes (RFC 7475 Section 6.1.1)
Prefixes that are too specific (RFC 7475 Section 6.1.3)
IXP LAN Prefixes (RFC 7475 Section 6.1.5)
The Default Route (RFC 7475 Section 6.1.6)
You also need to make sure that only authorized prefixes (those advertised by your AS and downstream customers) are being sent.
C. Inbound Prefix Filtering from Customers
General recommendations provided in Section 6.2.2.1 of RFC 7475 state that “only customer prefixes SHOULD be accepted, all others SHOULD be discarded.” The list of allowed prefixes should be manually built by the network provisioner after validating that customer prefixes are indeed allocated to the client by IP address management authorities.
In some cases, if customer advertises too many prefixes or has BGP clients of their own, customer-specific filters can be replaced with generic filters previously described in “Inbound Filtering from Private/Public/Transit Peers” section of the paper.
D. Outbound Prefix Filtering towards Customers
Depending on the customer preferences, they might want to receive
The default route only
Full Internet routing table
Subset of the Full Internet table (e.g. only the routes received via public and private peers, but not the transit routes)
The default route in addition to the Full or Partial Internet view
Generic recommendation described in Section 6.2.2.2 of RFC 7454 states that the following prefixes should not be sent to the customer:
Special-Purpose Prefixes (RFC 7475 Section 6.1.1)
Prefixes that are too specific (RFC 7475 Section 6.1.3)
The Default Route (RFC 7475 Section 6.1.6), for those customers not willing to receive it
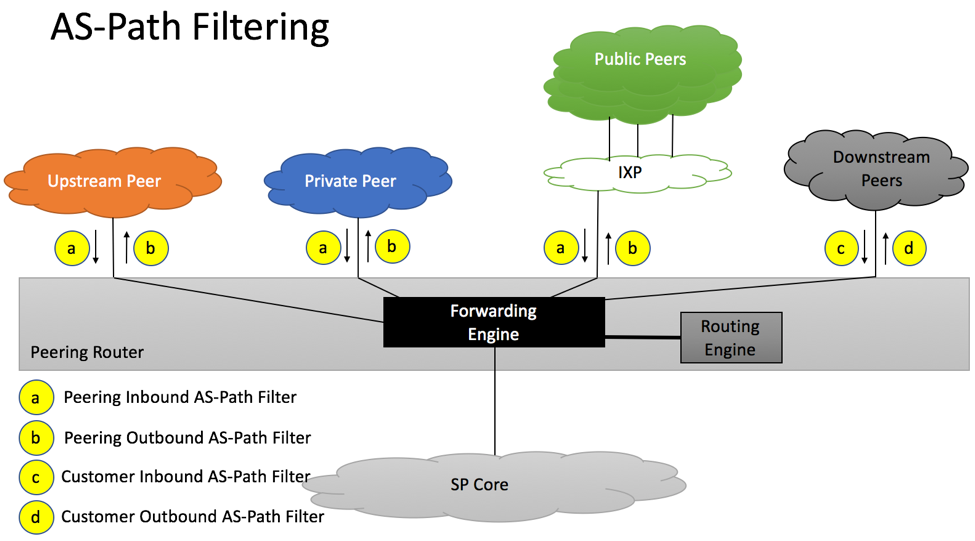
AS-Path Filtering
Section 9 of RFC 7454 provides a number of AS-Path Filtering recommendations that should be implemented on upstream/private/public peering sessions and customer sessions.
RFC7454 AS Path Filtering
Similar to how we analyzed Prefix Filtering recommendations in the previous chapter, we will review AS-Path Filtering recommendations below.
a. Inbound AS-Path Filtering from Private/Public/Transit Peers
Section 9 of RFC 7454 recommends the following:
Private AS numbers should not be accepted, unless used for special purposes such as black-hole origination
AS Paths with the first AS number not the one of the peer should not be accepted, unless originated by IXP’s router server
Do not accept your own AS number in the AS path
b. Outbound AS-Path Filtering from Private/Public/Transit Peers
Section 9 of RFC 7454 recommends the following:
Do not originate prefixes with nonempty AS Paths, unless you intend to provide transit for these prefixes
Do not originate prefixes with upstream AS numbers in the AS Path, unless you intend to provide transit to these prefixes
Do not advertise Private AS Paths, unless there is a special “private” arrangement with your peers
c. Inbound AS-Path Filtering from Downstream Customers
Section 9 of RFC 7454 recommends the following:
Only accept 2-byte and 4-byte AS paths containing ASNs belonging to the customer.
If this is not possible, accept only path lengths relevant to the type of the customer, while discourage excessive prepending
Do not accept your own AS number in the AS path
d. Outbound AS-Path Filtering from Downstream Customers
Do not advertise Private AS Paths, unless there is a special “private” arrangement with your customers
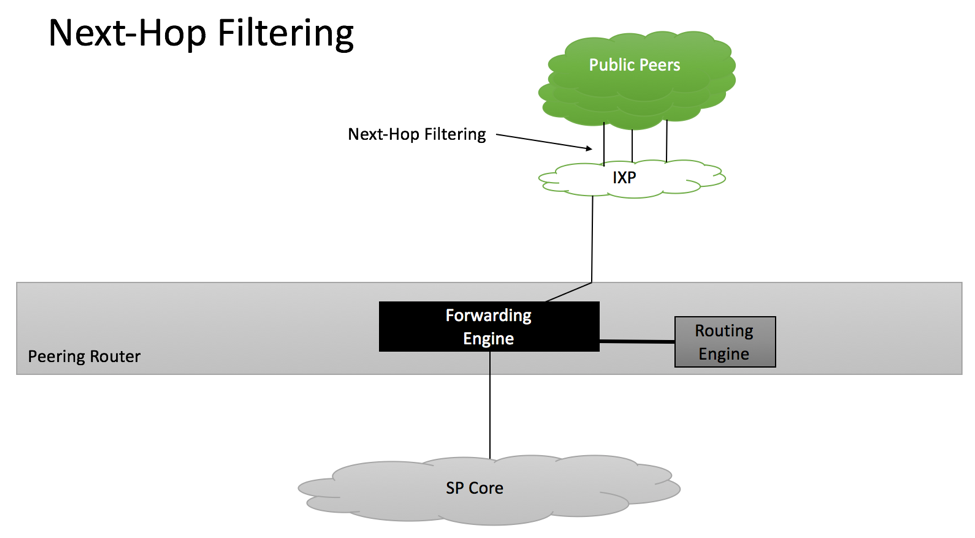
Next-Hop Filtering
BGP can advertise prefixes with a third-party next hop, thus directing packets not to the peer announcing the prefix but somewhere else. This mechanism is commonly used at Internet Exchange Points, where prefixes will be announced by IXP’s route-server.
RFC7454 Next Hop Filtering
Section 10 of RFC 7545 recommends the following policies at IXP locations:
For direct peering (without router-server), apply inbound BGP policy that would set next-hop for the accepted prefix to BGP peer IP address
For indirect peering (with IXP’s route-server), accept next-hop attribute advertised by the route-server
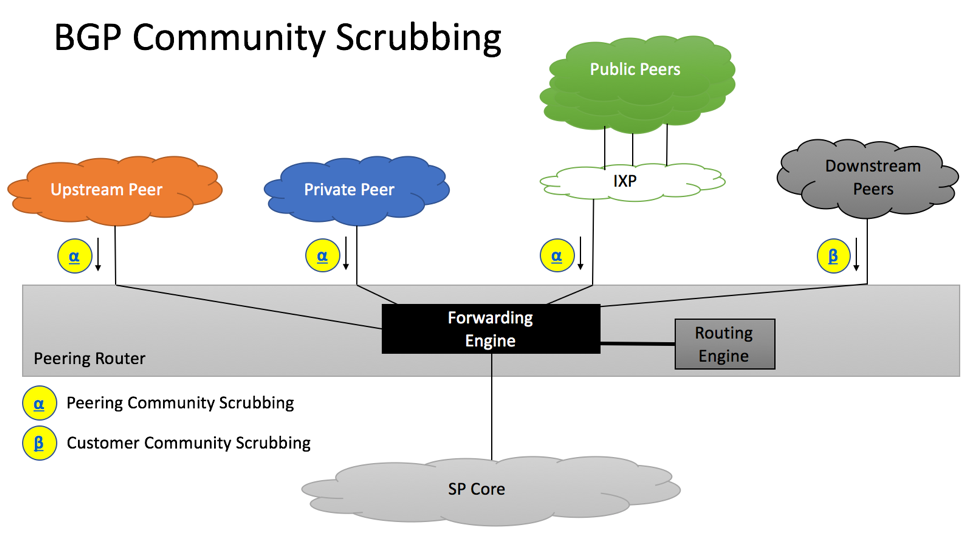
BGP Community Scrubbing
Section 11 of RFC 7454 provides the following optional community scrubbing recommendations.
RFC7454 BGP Community Scrubbing
Ingress BGP peering policy applied to transit/public/private and downstream peers should remove all inbound communities with SP’s number in the high-order bits, except for the ones used for signaling (e.g. setting BGP Local Preference).
Ingress BGP Policy should not remove other communities, as those communities can be used to communicate with upstream providers.
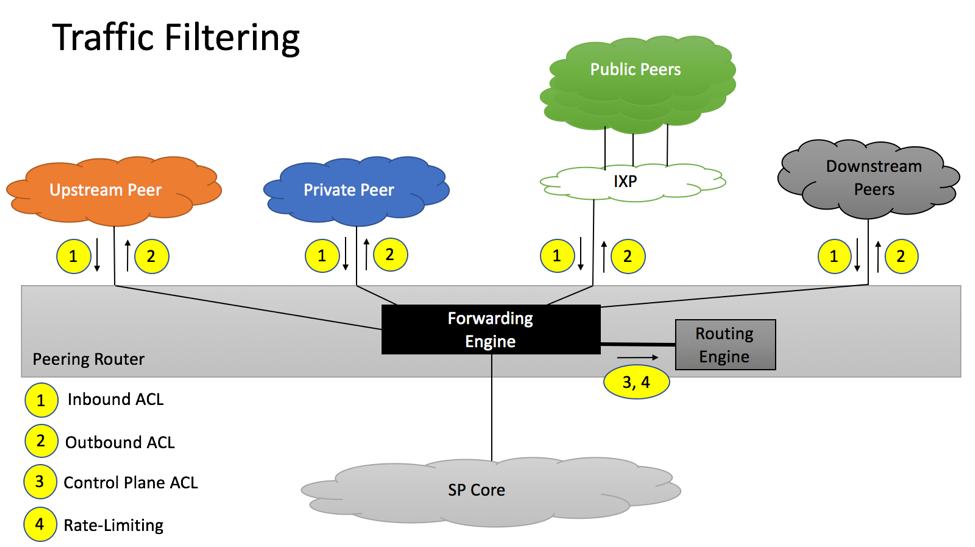
Traffic Filtering
Section 4 of RFC 7454 provides basic recommendations when it comes to traffic filtering and BGP.
RFC7454 Traffic Filtering
All packets destined to TCP Port 179 and not originated from addresses of configured BGP peers should be discarded. If supported, Control Plane ACL (point 3 on the diagram) should be used. If not supported, ACL applied to each peer-facing port (point 1) should be used.
If supported, BGP Rate-Limiting (point 4) should also be implemented, to make sure that the number of BGP packets per second does not exceed platform’s capability.
Generic Control Plane protection recommendations are out of RFC 7454 scope and are covered in RFC 6192.
BGP High Availability and Multihoming scenarios for Enterprise customers. Single ISP and Multi-ISP Redundancy.
Introduction
In this article, we will focus on building reliable Internet access to Enterprise branches. We will discuss single- and multi-homing scenarios and how BGP protocol can be leveraged in these deployments. While IPv4-based examples will be provided, this paper is also applicable to IPv6 deployment scenarios. The focus of this paper is Internet connectivity, although discussed techniques can be used for other types of connectivity, such as private IP VPN.
Enterprise BGP Internet Connectivity Options
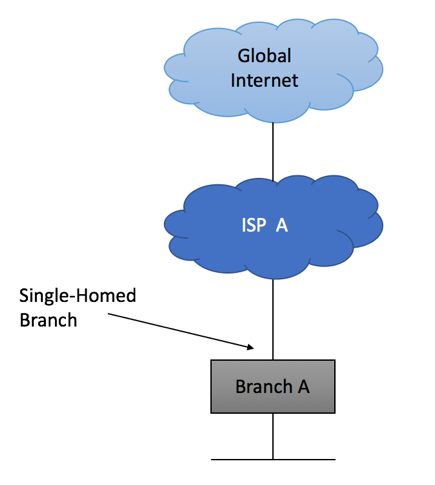
Single-homed network
As the name suggests, single-homed network is the network with just one external link. This is the type of Internet connectivity you have at home and the most common implementation scenario for small branch locations. It is simple, inexpensive and readily available. Your service provider might allocate a single IP address to the branch, requiring you to do NAT on border device, or might give you a large block allowing to assign Internet-reachable IP addresses to all branch devices.
Single Homed Site
If you were allocated only one IP address that is configured on ISP-facing interface of your border router, all you need to
Setup default route pointing towards ISP’s network
Select RFC1918 prefix that will be used to address your LAN infrastructure
Configure NAT
If ISP did provide you with a large Internet-routable block, you should come to an agreement on how this block will be advertised to the Internet.
The most common scenario is the static configuration on ISP’s edge router to point to your device. For example, branch A was assigned 128.66.1.0/24 prefix.
ISP will do two things:
Configure Static Route for 128.66.1.0/24 pointing to your Customer Premises Equipment (CPE) router
Redistribute this static route into one of dynamic routing protocols, making the rest of ISP A’s infrastructure aware of the network that was assigned to you
On your end, you will configure default 0.0.0.0/0 route to point to ISP A’s router, and assign given 128.66.1.0/24 network to CPE’s branch-facing interface.
Even in a single-homed scenario, it is possible to use dynamic routing protocols to advertise 128.66.1.0/24 prefix and accept default route from the ISP, although there is no technical benefit in doing this.
As your company grows, you might have additional offices to connect to the Internet. If these offices are connected in a similar fashion, you will still be using “Single-Homed” implementation.
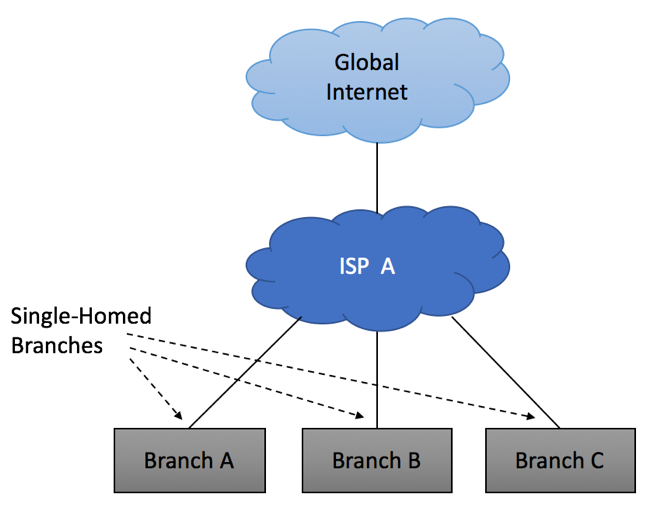
Single Homed Multiple Sites
It is not uncommon to use different Service Providers to connect different branches, yet all your connections will still be “Single-Homed.”
Single Homed Multiple Sites
Multi-Homing Overview
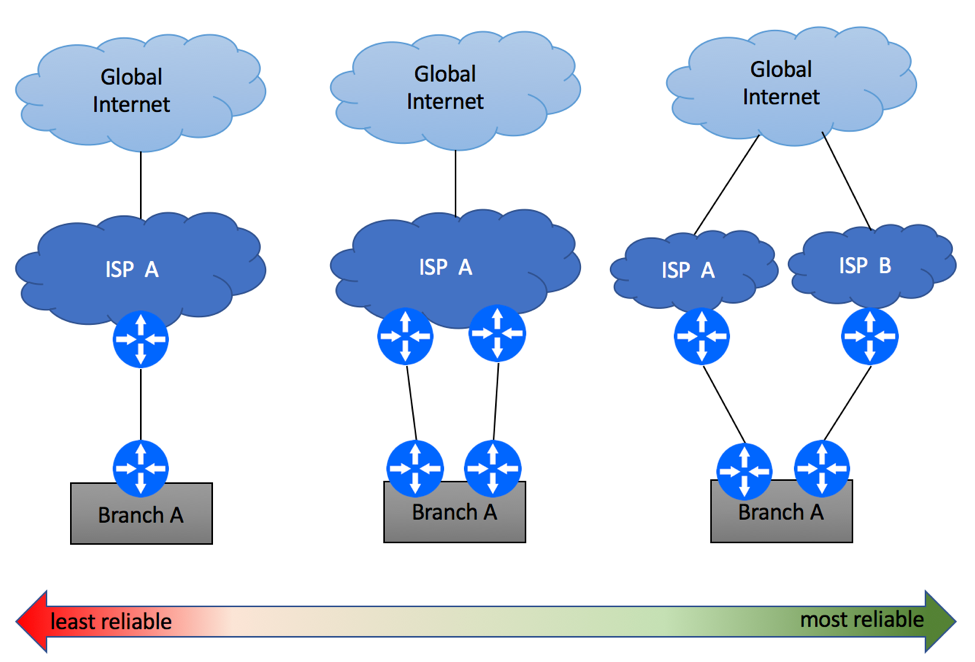
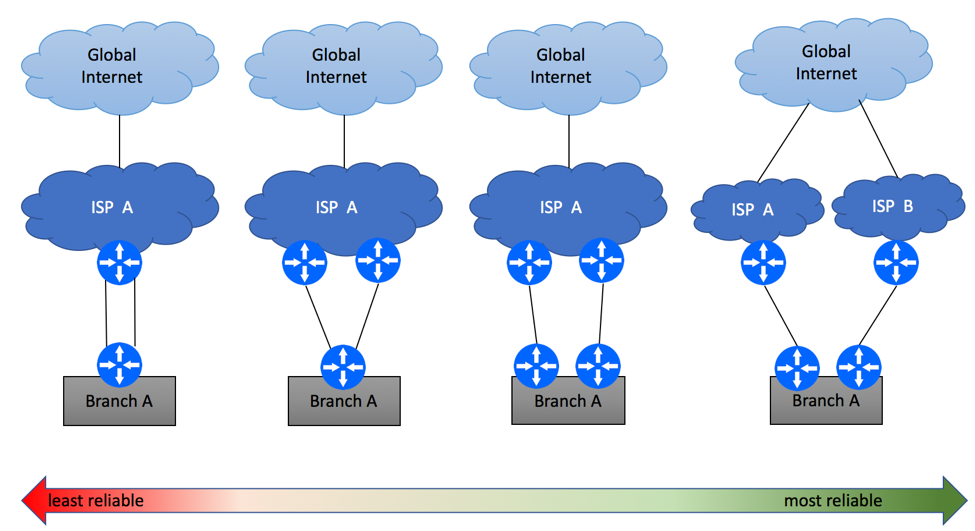
Assuming Internet connectivity is critical to your business, having a single link between ISP and your offices is a recipe for disaster. Equipment failure, fiber cuts, maintenance windows and DDoS attacks are common sources of Internet outages. In order to protect yourself, you should consider Internet multi-homing, where your branches will have an alternate path to the Internet in case of the primary link failure. While many Service Providers will be happy to sell you “redundant” Internet connectivity, it is important to understand that there are many levels of redundancy. Diagram below shows some examples, starting with the least reliable option of the secondary circuit being terminated on the same routers, and all the way to dual-homing scenario where your branch is connected to two ISP’s via two fully redundant paths.
Enterprise Multi Homing Scenarios
Multi-Homing Scenario 1 – Same PE / CE
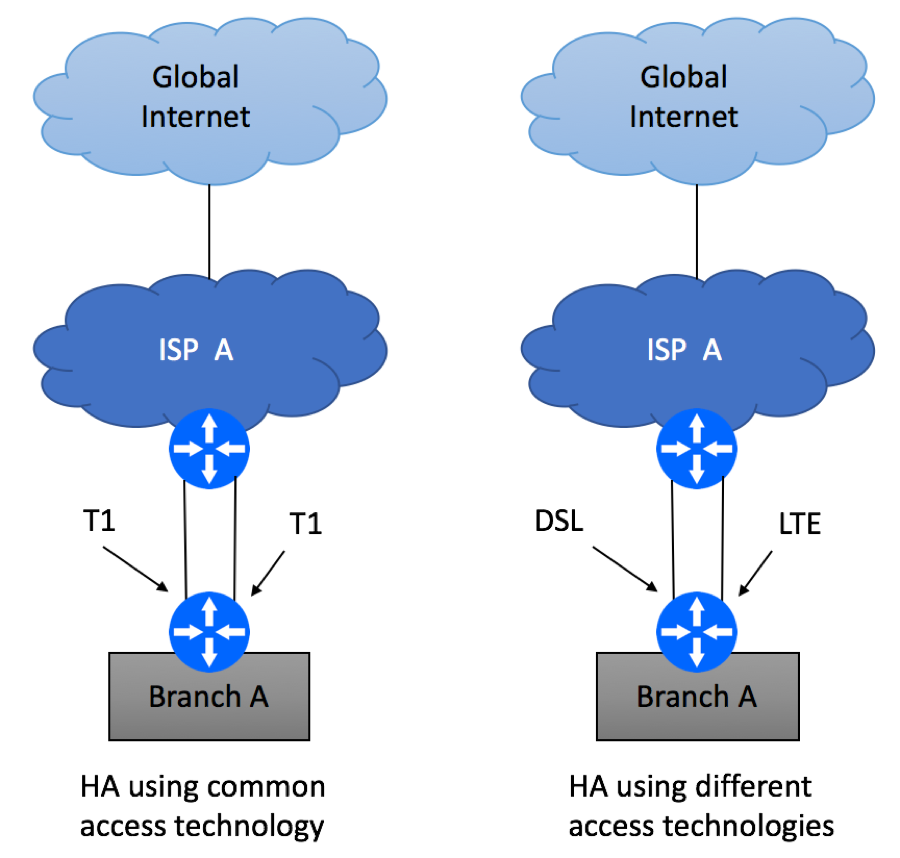
The simplest and the least reliable multi-homing scenario is where two physical links are terminated on the same Layer 3 devices on both ends. Depending on ISP’s capabilities, this service might be delivered over the same (e.g. two T1 circuits) or different access (e.g. DSL and LTE) media technologies. While it is recommended to avoid this type of setups if high availability is your primary concern, this might be the only option in some geographical areas.
Multi Homed Single PE/CE
Branch device configuration will be dictated by ISP’s service offerings and might include the following options
For common access technology, ISP might offer transport bonding, where one L3 paths is created from multiple physical links. This might be called T1 bonding, Ethernet Port Channel, Ethernet Link Aggregation, etc.
In case of dissimilar technologies, two L3 paths will be created. Most commonly, these two paths will be configured in Active / Standby mode, where the primary path takes all the traffic until it is declared unusable. Then the traffic will switch over to the secondary path. Failure detection mechanisms will vary from ISP to ISP and might include L2 OAM, BFD, L3 routing.
While BGP protocol can be used for failure detection and load-balancing in single PE / single CE scenario, it provides limited benefit to you as the end user.
Multi-Homing Scenario 2 – Different PEs / Single CE
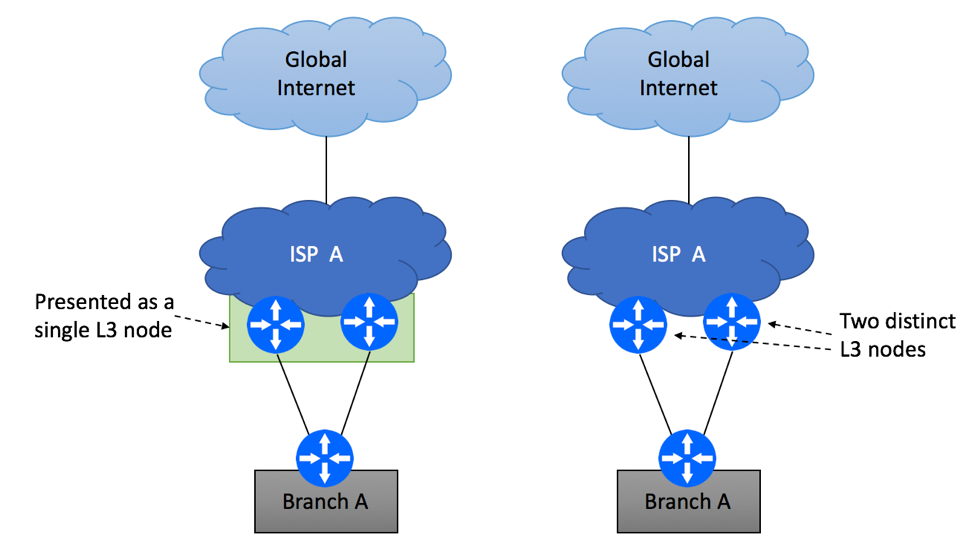
The second common scenario is the one where branch’s Internet circuits are terminated on two PE devices as shown below, while you continue to utilize single device at the branch site.
Multi Homed Dual PE Single CE
Your ISP might have the capability to join two physical devices into a single logical L3 node, meaning that the rest of the network (including CPE at your site) will see this combined system as a single router. The obvious benefit of this type of technology is improved availability of the service, as failure of one node will not cause an outage for dual-homed customers. There are also some known drawbacks, for example software bug or configuration mistake is likely to impact both ISP’s nodes at the same time.
The second scenario is the one where two PE devices are completely independent of each other. Most likely, this will mean that one of the physical paths will be designated as “primary” and the second as “secondary.” Both static routing and BGP are commonly used for these deployments, so let’s review both cases.
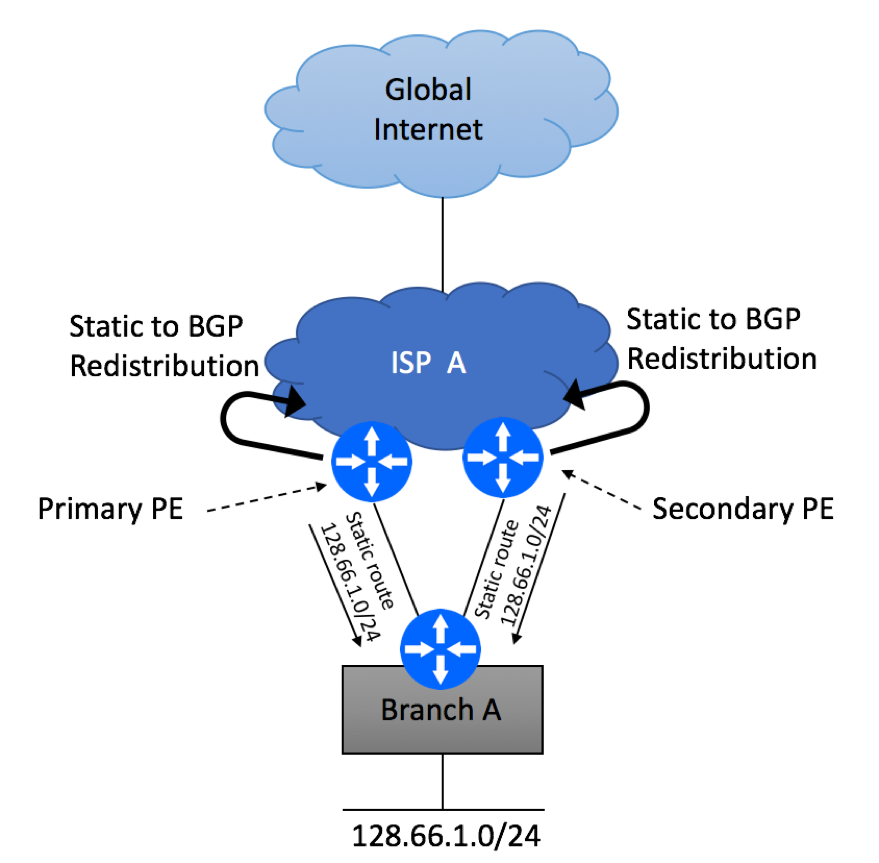
If you opt out to use static routing, ISP will configure static routes on their primary and secondary PE devices pointing to your CPE as shown below. They will then redistribute these routes into their routing protocol of choice, such as IBGP.
Multi Homed Dual PE Single CE Static Routing
ISP will also need to make sure that there is a reliable mechanism in place to detect link failure condition between your branch CPE and PE router. BFD is a popular option, although not all platforms can support it.
On the CPE side, you’ll need to configure two static routes pointing to the primary and the secondary PE devices. You have a choice of configuring these two routes with the same metric (admin distance in Cisco’s terms) or different metrics. If both of your paths have the same characteristics (bandwidth and latency), configuring equal metrics is a viable option. If your paths are not the same, for example 10Mb Ethernet as primary and T1 as secondary, configuring the primary one with lower metric and the secondary one with higher metric would make more sense.
If you decide to use BGP instead of the static routing, you’ll need to do a few things:
Request Private BGP Autonomous System (AS) Number from your ISP, unless you have a public AS assigned to you by the Regional Internet Registry
Find out what BGP AS is being used by your Service Provider
Agree on MD5 keys to use for your EBGP sessions
Ask your ISP to advertise default-route only. There is no need for you to get the full BGP view, too many routes might overwhelm your CPE device.
Ask what communities are supported by your ISP to identify the primary and the secondary paths
Advertise the prefix that was assigned to you with corresponding communities
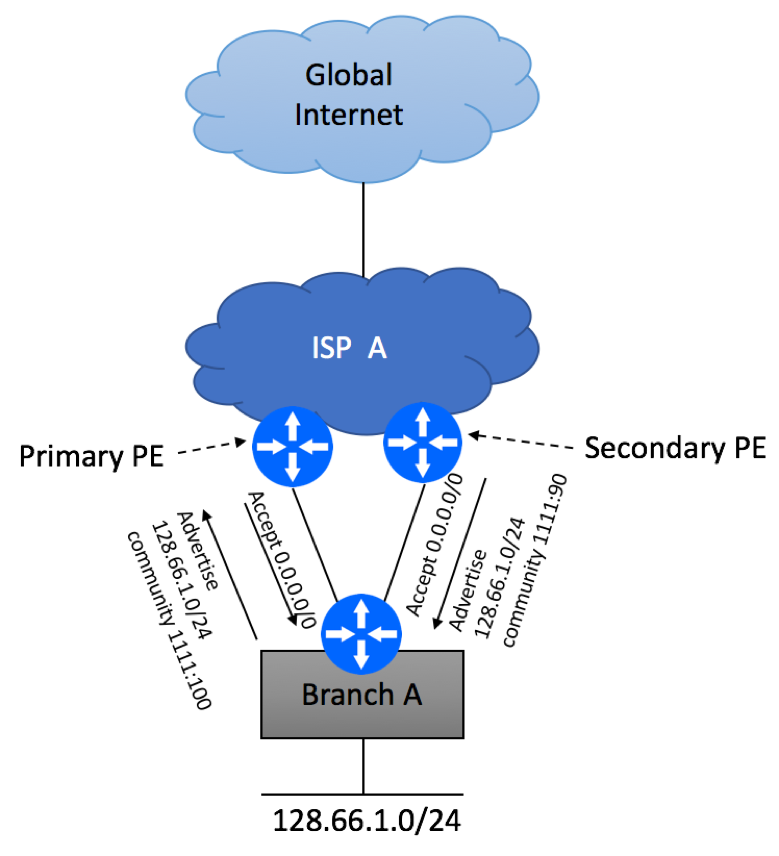
Let’s assume that your ISP supports the following communities:
1111:100 – primary Internet path
1111:90 – secondary Internet path
Configure BGP sessions as shown below. Make sure you only advertise the prefix assigned to you by the ISP and not your internal routes.
Multi Homed Dual PE Single CE BGP Routing
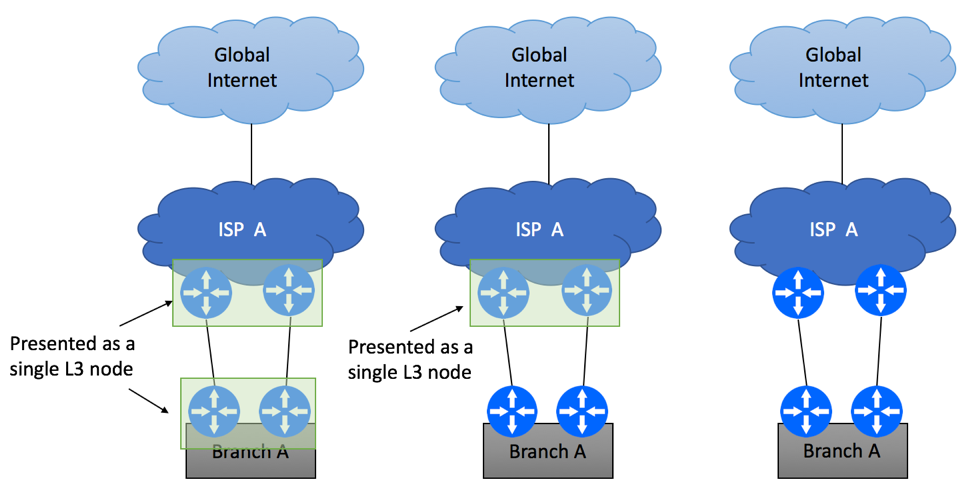
Multi-Homing Scenario 3 – Different PEs and CEs
The third scenario requires physical router redundancy on both Service Provider’s and Customer’s sites. There are a few deployment options to be considered.
Analogous to how Service Provider might combine two physical nodes to work as a single L3 device, you can employ similar technique on your end. This can be done by leveraging proprietary vendor implementations, such as Virtual Switching Systems, Virtual Chassis, firewall clusters, etc. If you take this route, you will effectively create a single L3 node, so configuration techniques discussed in “Scenario 2” section would be applicable to this use case.
Multi Homed Dual PE Dual CE Options
If two CPE’s are not combined, you will need to rely on routing protocols to forward traffic to and from the Internet. Both static routing and BGP can still be used in a dual-CPE deployment. Let’s discuss static routing deployment first.
With static routing, your Service Provider will configure static routing and routing redistribution the same way they’d have configured it in a single-CPE scenario, but configuration of the CPE device at the customer site will be more complex.
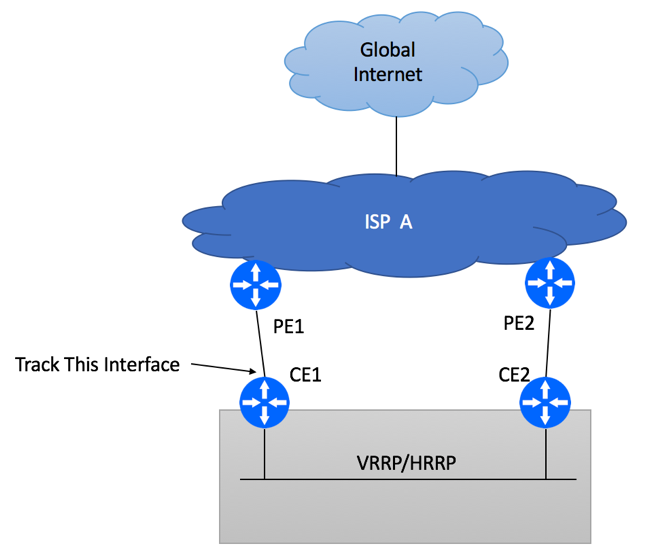
Multi Homed Dual PE Dual CE Options with HSRP/VRRP
On both CE1 and CE2 devices, configure static default routes pointing to corresponding PE devices
Decide which CPE device will be used as the primary router for Internet connectivity
Configure either VRRP or HSRP between your CPE devices. Primary device should have higher VRRP/HSRP priority. Allow pre-emption.
Configure upstream interface tracking and VRRP/HSRP priority change on upstream link failure.
As an additional protection mechanism, consider enabling IP SLA to monitor the status of ISP’s PE device modifying HSRP/VRRP priority if the device becomes unreachable. This helps to avoid blackholing if CE1 is unable to detect link failure or if PE1 experiences issues while keeping interfaces in “up” state.
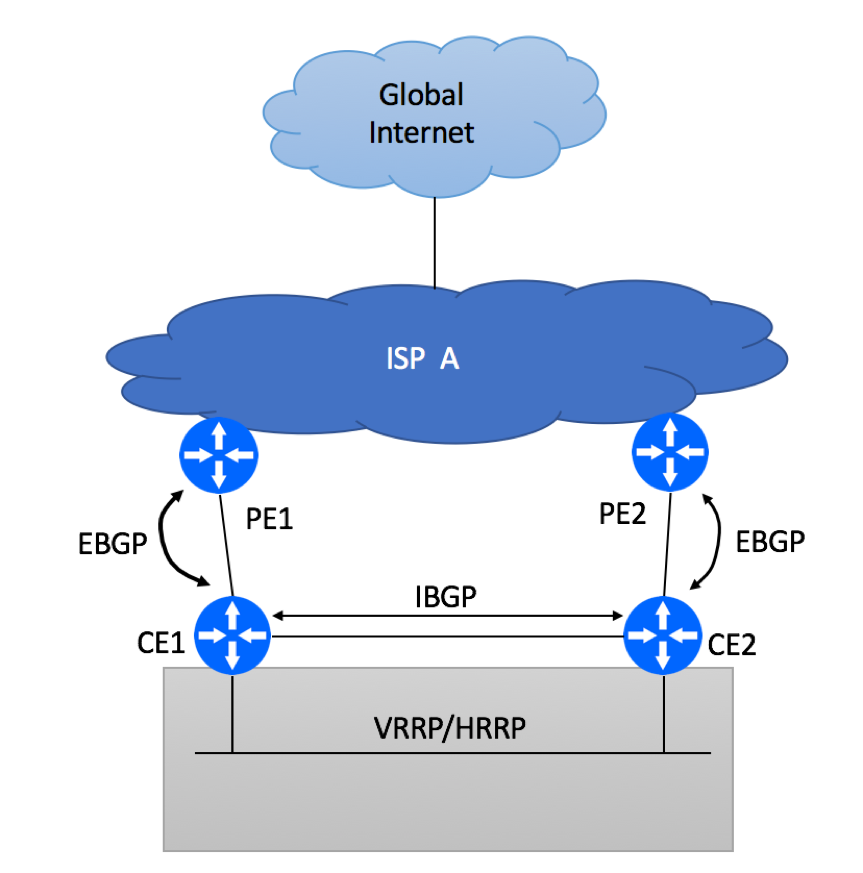
While static routing configuration might be preferred by some network administrators in dual-PE / dual-CPE deployment due to its simplicity, BGP-based configuration is a valid and in many cases preferred alternative.
Multi Homed Dual PE Dual CE Options with HSRP/VRRP and BGP
To get BGP going, follow these configuration steps:
Request Private BGP Autonomous System (AS) Number from your ISP, unless you have a public AS assigned to you by the Regional Internet Registry. You will only need one AS Number as both CE devices belong to the same site.
Find out what public AS is being used by your Service Provider
Agree on MD5 keys to use, this will secure your EBGP session
Ask your ISP to advertise default-route only. There is no need for you to get the full BGP view
Ask what communities are supported by your ISP to identify the primary and the secondary paths
Advertise the prefix that was assigned to you with corresponding communities via EBGP session
Configure IBGP session between CE devices. The purpose of this IBGP session is to exchange the default route learned from the ISP between CE devices. Under normal conditions, this IBGP-learned route will not be used as EBGP path will be preferred. But IBGP-learned prefix will get utilized when CE-PE link failure.
Configure VRRP between CE devices.
Configure upstream interface tracking and VRRP/HSRP priority change on upstream link failure. Although with IBGP session in place, you will not experience traffic blackholing, VRRP failover will help you to bypass CE router with failed upstream link.
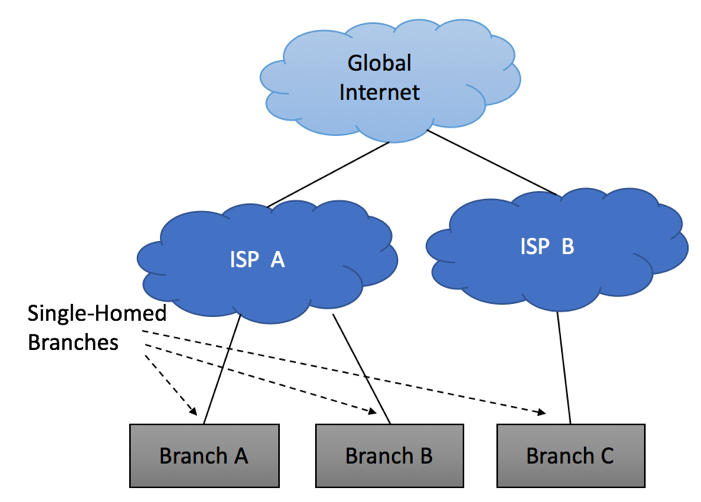
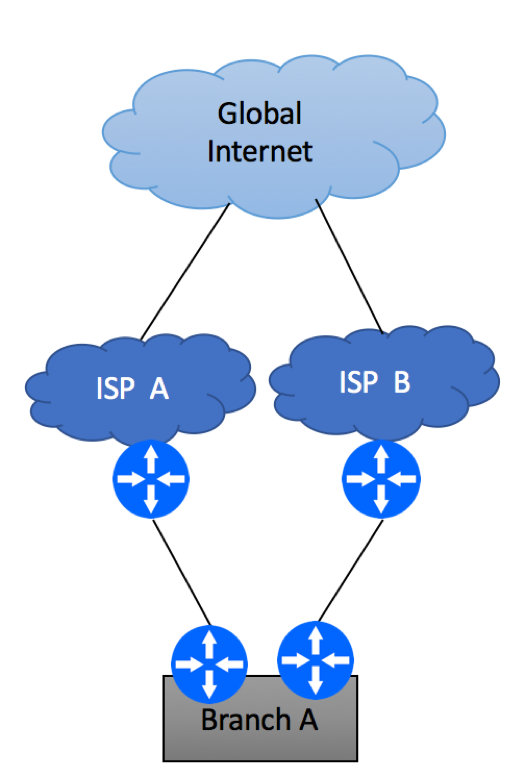
Multi-Homing Scenario 4 – Multiple ISPs
The last and the most reliable multi-homing scenario is the one where your network is connected to different service providers. As always, there are multiple flavors of this implementation.
Multihoming to different ISPs
But before we go into implementation details, ask yourself these questions:
Are there any services hosted within your branch location that need to be reachable via the Internet? An example of these services can be VPN concentrator, Web, Mail or File Server.
Can those services support multiple external IP addresses and take care of seamless failover if public IP changes? For example, Email server can be assigned two public IP addresses – one provided by the ISP A and the second IP provided by ISP B. Two DNS MX records pointing to these IP addresses will take care of the service failover. Other services, such as Web server, while capable of being reachable via multiple external IPs, will not perform well if one of the IP addresses goes away. DNS records will need to be updated to purge no longer reachable IP address, sessions in progress will drop and user experience will suffer.
Can non-graceful failover be tolerated for inside-out connectivity (users in the branch trying to reach the Internet)? Is it acceptable if all user’s session will drop and users will need to reconnect to the resources they’ve used on the Internet?
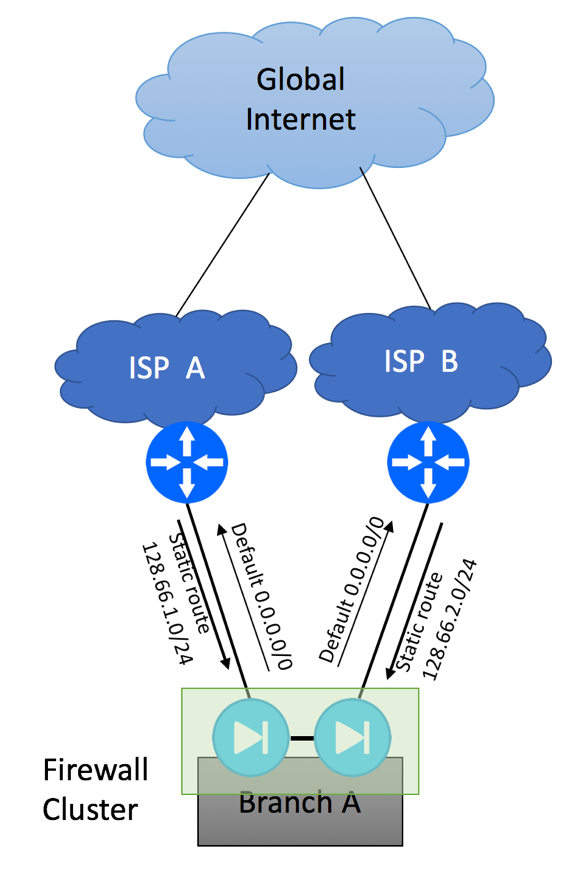
If your users can accept short period of service interruption when traffic fails over from one ISP to another, and you are not hosting any mission critical Internet-facing services in your branch location, you have a simpler problem to solve. This is nothing but a single-homed network scenario we described at the very beginning of this article, repeated twice. Your service providers will allocate IP Prefixes from their respective routable IP pools, and you will have two independent IP ranges to assign to the end devices at your branch site. Most network administrators would setup a firewall cluster and configure NAT pools using IP addresses provided by the ISPs for NAT pools. As you will be configuring two default routes on your firewall cluster pointing to two different Service Providers, there will be a need to implement policy-based routing on your device to make sure traffic with a wrong source IP is not being sent. For example, you got 128.66.1.0/24 allocation from ISP A and 128.66.2.0/24 from ISP B.
Multihoming to different ISPs with Firewall Cluster
Please note that you should never try to send packets with source IP in 128.66.1.0/24 range to ISP B and packets with source IP 128.66.2.0/24 to ISP A, as ISP’s anti-spoofing mechanisms such as uRPF might drop these packets. Your policy-based routing configuration should check the source IP of the packet and send it via correct egress interface.
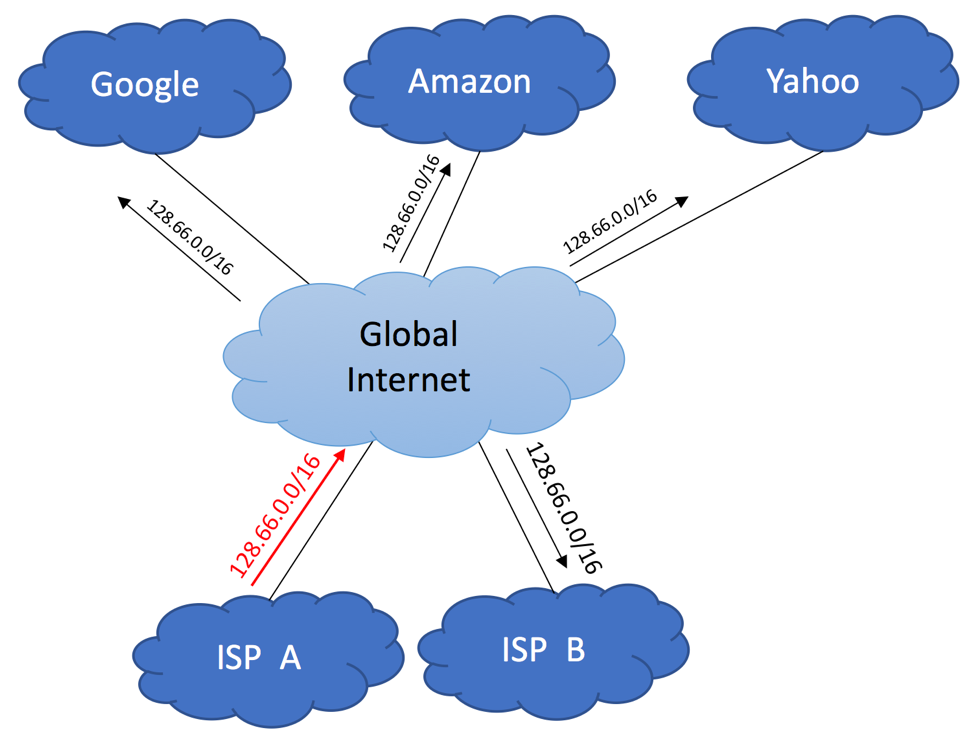
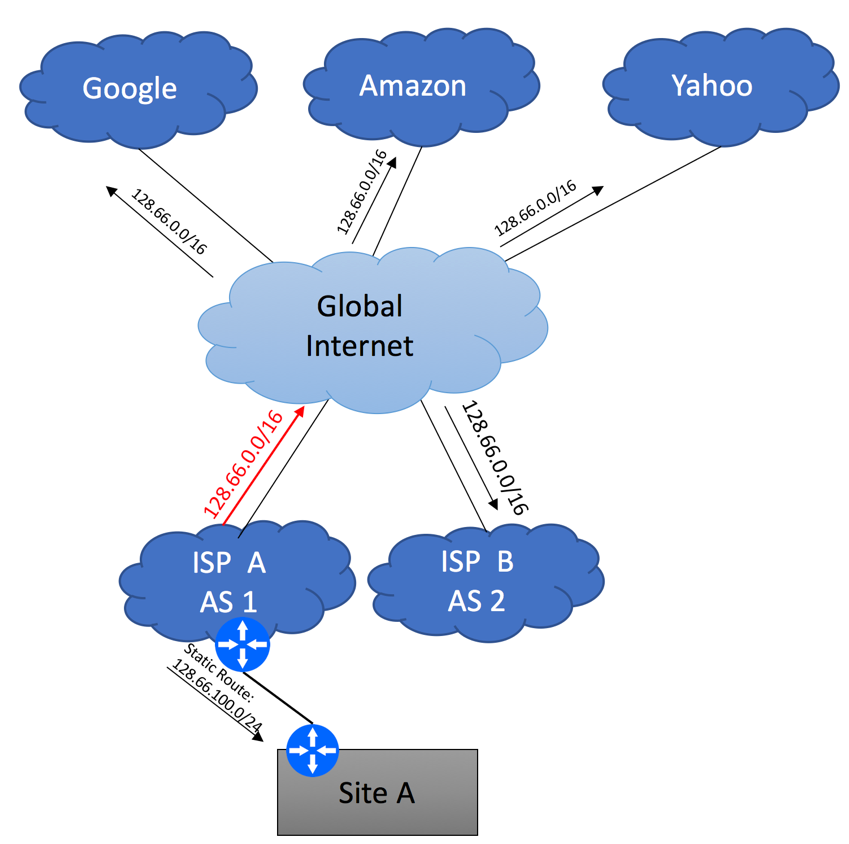
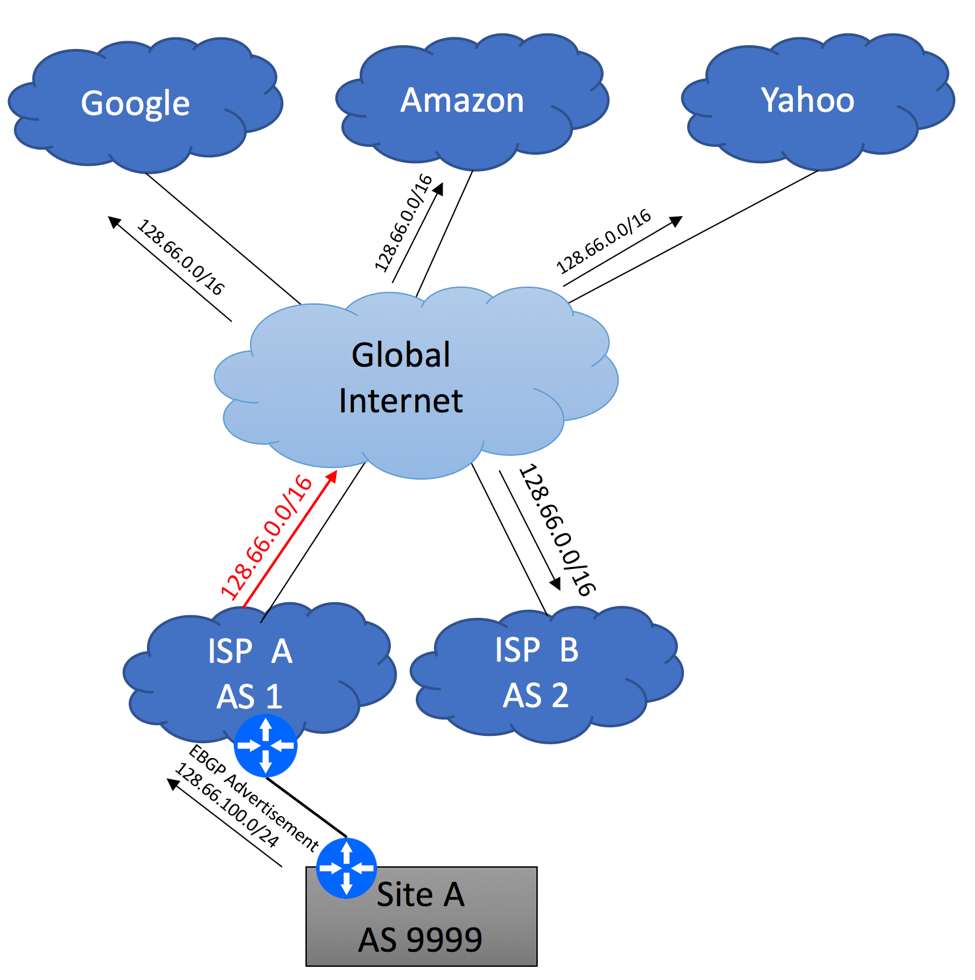
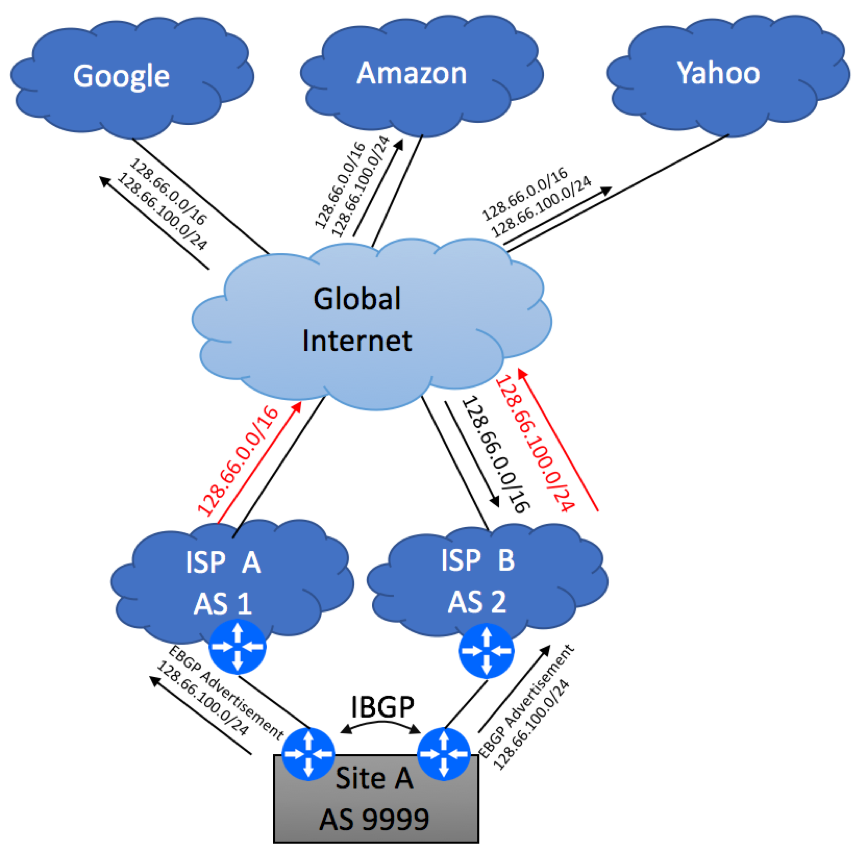
If the services hosted in your branch location require 100% uptime and cannot allow external IP change, you must implement BGP. You’ll need to follow the steps outlined below:
Make sure your Internet providers can support BGP over your transport media. For example, some ISPs will allow you to run BGP over T1 and Ethernet-based links but not over DSL and 3G and LTE.
Request Public Autonomous System (AS) number from one of the Regional Internet Registries (ARIN, RIPE, APNIC, LACNIC or AFRINIC). In order to qualify for AS, you will need to meet the following requirements: “If you are qualifying under the multihomed policy you will need to provide the exterior gateway protocol to be used, the IP addresses currently in use on your network, the AS number and name of each of your upstream providers and/or peers along with contractual verification of service with at least two of them.” Source: http://teamarin.net/2014/01/31/how-to-request-an-asn-from-arin/
Request publicly-routable IP prefix. This might become the most difficult part of your project. Due to IPv4 depletion, it is very unlikely that you will be able to get direct allocation from one of the RIRs. This means that you will need to get routable IPv4 space from one of your ISPs, and get their permission to start BGP advertisement of this space from your own AS via a different ISP!
Here is an example to illustrate this scenario. Imagine, that ISP A was assigned 128.66.0.0/16 by RIPE. Being a good Internet citizen, ISP A advertises this aggregate block via BGP to the Internet, while suppressing smaller advertisements.
Multihoming to different ISPs using BGP
ISP B receives this advertisement as a part of the Global Routing Table update either from ISP A (assuming ISP A and ISP B maintain direct peering relationships), or via 3-rd party service provider. The same applies to all other companies that participate in the global BGP.
Now, let’s pretend that ISP A assigned 128.66.100.0/24 prefix to your Site A. Information about this 128.66.100.0/24 network would need to be propagated within ISP A’s network, so that traffic coming from the global Internet could find its way to your circuit, but specific 128.66.100.0/24 advertisement does not have to be sent to the Internet. 128.66.0.0/16 that is currently being advertised already includes 128.66.100.0/24 block, making it reachable from everywhere. More specific 128.66.100.0/24 advertisement originated from your Site A will be suppressed by ISP A and will not be leaked to the Global Internet.
Multihoming to different ISPs using BGP
It is not important if ISP A uses static routing between their PE device or rely on BGP – in order to be good internet citizens, they should suppress 128.66.100.0/24 advertisement.
As your end goal is to start advertising 128.66.100.0/24 from your own AS, let’s review the following example, assuming that ISP A’s public AS number is 1, ISP B’s Public AS number is 2 and your company got assigned AS 9999.
In the initial state, when ISP A receives 128.66.100.0/24 advertisement originated from AS 9999 they will not propagate it to the Global Internet. This is perfectly fine, as the only way for the Internet to reach Site A is via ISP A, and ISP A already originates an aggregate 128.66.0.0/16 block. By sending your 128.66.100.0/24 to the rest of the Internet, ISP A will increase the size of Global BGP table for everybody without achieving any benefits.
Multihoming to different ISPs using BGP
Your next step is to establish EBGP peering between Site A and ISP B and advertise 128.66.100.0/24 to ISP B. You will need to get an approval from ISP A for this, and you will need to present this approval to ISP B.
As ISP B does not own 128.66.100.0/24 or any part of 128.66.0.0/16, there is no way for the to aggregate /24 prefix, so they will re-advertise your 128.66.100.0/24 prefix to the rest of the Internet. Now we observe an interesting paradox, where the global Internet starts using ISP B to send traffic to your Site A, despite the fact that 128.66.100.0/24 prefix is owned by ISP A. You can attempt to do AS prepend on your advertisements towards ISP B, but it will not make a difference, as more specific route will always win. The only traffic you might observe on your ISP A – Site A link is the traffic originated from ISP A’s direct clients.
Multihoming to different ISPs using BGP
If redundancy is your only concern and ISP A is fine with the fact that the majority of your traffic is being sent via their competitor, you can stop here. Failover will work as it is. If your CE2 or CE2 to ISP B’s link goes down, or even if the entire ISP B disappears, traffic will get rerouted via ISP A thanks to the aggregate 128.66.0.0/16 block being advertised by ISP A.
If this situation is not acceptable and you due to load-balancing requirements or ISP A insists on seeing CE1 – ISP A being used under normal conditions, ISP A will have no choice but to stop suppressing your specific advertisement and start leaking 128.66.100.0/24 originated from AS 9999 to their peers. This will take care of the traffic coming to the Internet and destined to your network. It is not possible to say ahead of time what percentage of the incoming traffic will come via ISP A vs ISP B, but there will be some level of load balancing.
The next step is to figure out the best way to send the traffic from your site to the Internet. The simplest solution is to accept the default 0.0.0.0/0 route from both ISP A and ISP B. If you have a preference for the primary path, you can configure ingress BGP policy and set higher BGP local preference for the default route coming from either ISP A or ISP B. If your routers are capable of supporting the full BGP view (meaning they can handle close to 1Mln routes), you can request your ISPs to send you the full Internet routing table. Leave it to BGP to decide what path to take to reach the Internet destinations. And don’t forget to configure IBGP session between your CE devices!
In this article, we will discuss various types of Internet peering. You need to have basic knowledge of BGP protocol to better understand this paper, so if you are not familiar with BGP, we suggest that you start with the following Wikipedia article: https://en.wikipedia.org/wiki/Border_Gateway_Protocol
As a peering administrator, you are responsible for selecting the best peering strategy for your company. In order to determine what’s best for your organization, you need to identify your peering goals. Very frequently, these goals might be at odds. Let’s start with reviewing possible peering objectives and then continue with a discussion on why it is difficult to satisfy all of these requirements at the same time.
Typical Service Provider would have the following peering objectives:
Achieve High Availability – no matter what happens, your network should be able to reach any Internet destination
Maintain Low Latency and Low Packet Loss – you should always try to pick the path with the lowest possible latency and minimum packet loss
Minimize Traffic Cost – achieve the best connectivity possible at the minimal cost possible
Maximize Revenue – this often means that you want to attract more customers’ traffic than your competitors
By going through the objectives list, it is clear that the low-cost goal is at odds with other stated objectives. To achieve the best connectivity and high availability, you’d need to peer with as many companies as possible, but peering costs money. At the same time, improved peering might lead to increased revenue, as your network will attract more traffic.
The reality of the situation is that you will need to find a compromise by determining the number and types of peering that is right for your company.
Let’s list the types of peering sessions and then reveal technical details associated with each of them:
Upstream, also known as Transit Peering
Private Peering
Public Peering
Downstream, typically Customer Peering
Figure below shows an ISP (labeled as “Your Company”) connected to different types of peering partners.
Types of Peering
Upstream Connectivity / Transit Providers
Unless you work for the elite group of Tier 1 providers (https://en.wikipedia.org/wiki/Tier_1_network) you will always need to buy Internet Transit Service from one or more service providers. This Transit Connectivity is sold by Upstream providers, who will feed you the full Internet BGP view table and, at least in theory, will deliver your packets to any device on the Internet either over their own network, or via their partners and clients. Selecting the right upstream provider or group of upstream providers is one the most important decisions you’ll need to make while building your network. Reliability, Connectivity types, cost per Mb are just some of the factors that will influence this decision. We’ll talk about selecting the right Upstream later in this article.
By accepting the full BGP table from Transit provider, your routers’ routing tables will get populated with the information about each and every IPv4 (and possibly IPv6) prefix currently present on the Internet.
In return, you will advertise your locally-originated routes, as well as routes received from your BGP customers.
Upstream / Transit Peering
Most organizations will employ direct transport links with their Transit providers, although it is possible (but typically not cost-effective) to leverage physical transport provided by an Internet Exchange Point (IXP) for upstream connectivity.
Private Peering
Private peering is the type of peering where two parties establish BGP connectivity over direct transport link and exchange information about routes originated in their own and their customers’ networks. While most of private peering arrangements are settlement-free, meaning that companies do not pay each over to exchange traffic over private links, there are also cases where an ISP might refuse to establish settlement-free relationships with your company, but is willing to sell access to their customer base at a discount, as compared to buying full transit connectivity from that provider.
It is also important to remember that while the traffic exchange might be free, there will be a cost associated with the physical transport (e.g. 10GE link over DWDM), as well as the cost of a port on your router where this link will be terminated.
In some cases, it might be difficult to predict how much traffic you will exchange with specific peer before establishing direct peering relationships. Although various traffic analysis tools such as Arbor SP might provide you with an estimate, we find that these predictions are not always reliable.
When possible, you should start with establishing Public peering relationships with a prospective peer and, assuming the amount of traffic justifies this, later convert to the Private peering relationships.
Figure below depicts private peering relationships with “Your Company”. Depending on the size of the peer, you might receive from them anywhere from a few routes to tens of thousands of routes. Large number of routes does not necessary mean high volume of traffic. Big CDN provider with just a few prefixes can deliver much more traffic to your network, than an ISP with thousands of prefixes in some remote geography.
Private Peering
Public Peering
Public peering is a type of relationship where two companies exchange IP traffic via one of public Internet Exchange Peering Points (IXP). The main advantage of peering at IXP is the ability to establish sessions with a large number (often hundreds) of partners, without the need to build individual transport links with all these peers. While most of peering relationships at IXP’s are settlement-free, there is often an initial connectivity cost, as well as a monthly recurring cost charged for IXP connectivity. In addition to that, there is a cost associated with a transport link between your peering router and IXP port. In fact, IXP charge and the transport cost when added together, might exceed the cost of buying IP transport from one of the Transit Providers.
Public Peering
With this being said, it is always good to be aware of the peering options in your geography, as not being connected to large IXPs might put you at a competitive disadvantage.
List of Internet exchange points by size can be found here:
It is also important to note, that presence at an IXP does not automatically mean that you will be able to peer with all Exchange members. While some IXP participants have open peering policy, meaning they will exchange traffic with any other IXP member, other organizations are more restrictive and you will need to negotiate peering relationships with them on a case-by-case basis.
Downstream (Customer) Peering
BGP peering with your customers, also known as Downstream peering, is the type of a relationship where your company performs the function of a Transit Provider. IP Prefixes received from downstream peers should be re-advertised to all your peers, including Public, Private, Transit, as well as your other BGP-speaking customers.
Now that you’ve been introduced to various types of peering, let us review a few use cases.
Case Study – Small ISP Startup
You were asked to recommend a peering and transit policy for a small regional Internet provider called “ISP Startup.” This company operates in the country where two large incumbent providers control nearly 80% of the country’s user base. These incumbents buy transit connectivity from various Tier 1 ISPs. Incumbents peer with each other, but will not join settlement-free peering relationships with small local ISPs.
There is an Internet Exchange point in the country. Some Global Content Delivery Networks (CDN), small local ISPs and Enterprises are connected to this IXP.
At the moment, “ISP Startup” does not have any BGP clients, but plans to acquire them in the future. The current goal is to minimize the Internet transit cost, while providing the best possible service to end users.
Based on the information provided, our “ISP Startup” has the following connectivity options to consider:
Buy transit from “Incumbent A”
Buy transit from “Incumbent B”
Buy transit from Global Tier 1 providers used by one or both Incumbent ISPs
Buy transit from Global Tier 1 providers not used by Incumbent ISPs
Buy transit from Global Tier 2 / Tier 3 providers operating in the country
Connect to Internet Exchange Point and try to establish settlement-free sessions
Figure below depicts connectivity alternatives for the new ISP.
Small ISP Peering
This use case will not be complete without some assumptions about transit costs.
Let’s use the following model:
Option
Price per Gb/month
Remarks
Incumbent A
$200
Incumbent B
$250
Tier 1 – A
$180
Tier 1 – B
$220
Used by Incumbents
Tier 1 – C
$300
Tier 2 – A
$140
Tier 2 – B
$160
IXP
$50
Will not provide transit
IXP is the cheapest option by far, but it is not a substitute for Transit Internet connectivity. It might be relatively inexpensive to connect to an IXP, but our “ISP Startup” may be disappointed by the amount of traffic exchanged over IXP links. While there are many contributing factors (a type of ISP’s own customer base, number and type of IXP participants), you should not expect to offload more than 30% of your traffic to IXP. In fact, this number might be significantly lower than that. Your next decision is to select one or more upstream providers. If you base your decision on cost, “Tier 2 – A” ISP is the winner. You would establish at least two redundant links to “Tier 2 – A”, and might build a non-redundant link to the IXP as shown below.
Small ISP – Single Upstream
Various traffic flow scenarios under normal conditions are depicted below:
Small ISP – Single Upstream Traffic Flow
While this design allows you to keep the cost low, it has a few major shortcomings:
Small ISP – Multiple Upstreams
There is no upstream redundancy – failure of “Tier 2 – A” ISP would take your company off the air.
You customers might experience high latency while communicating to Incumbent’s clients, as they’d need to cross multiple networks
If your ISP Startup grows and you acquire BGP customers of your own, it will be difficult to attract transit traffic, as your network will be a few AS hops from the majority of Internet destinations.
Let’s look into an alternative where ISP Startup connects to “Incumbent A”, “Tier 1 – A” and IXP.
Link to “Incumbent A” will provide you with direct access to “Incumbent A’s” customer base, as well as with a short path to “Incumbent B’s” clients. IXP connection will help you to reach the remaining local ISPs and provide access to CDN networks. Direct “Tier 1” connection will give you access to the rest of the Internet.
If Tier 1 link were to fail, you would reroute your traffic to the Internet via Incumbent A. If links to “Incumbent A” or IXP were to fail, you would reroute via “Tier 1” ISP. In addition to that, it will be much easier to attract transit internet traffic to your AS, if you peer directly with one of the global Tier 1 providers.
Let us compare monthly costs, based on the assumption that your network needs 100Gb pipe, of which 10% can be offloaded to IXP, 20% is destined to Incumbent providers and the rest needs to go to the Internet.
Option 1:
IXP: 10Gb @ $50 = $500
Tier 2 – A: 90 Gb @ $140 = $12,600
Total: $13,100 per month
Option 2:
IXP: 10Gb @ $50 = $500
Incumbent A: 20Gb @ $200 = $4,000
Tier 1 – A: 70Gb @ @180 = $12,600
Total: $17,100 per month
As you can see, Option B is ~30% more expensive. You will need to decide, if increased redundancy and improved latency warrants this premium.
Case Study – Medium-Size ISP Operating in 3 Regions
In this case study, we will analyze the scenario of an ISP operating in 3 different geographical regions using one common AS Number. We’ll call these regions West – North – East, although in the real life they can represent three cities, countries or even continents.
Medium Size ISP
Similar to the previous example, this Medium-Size ISP needs to decide on the best connectivity options, while delivering exceptional service to its customers at the lowest possible price points.
Let’s review Transit, Public and Private peering options.
Transit Peering
Because of the size of the company and its desire to attract BGP clients, our ISP is inclined to buy transit from Tier 1 ISPs only. It believes that sometime in the future it will be in the position to negotiate settlement-free peering with Global Tier 2 providers, making it not feasible to buy transit from one of them today.
When it comes to choosing an ISP, the first possible approach is to select three different transit ISPs, one per region.
Medium Size ISP – Upstream Option 1
The clear advantage of this approach is the resiliency of Global Internet connectivity. If one, or even two links to Tier 1 ISPs were to fail, traffic could always be rerouted via the remaining connections.
It is also believed, that direct connectivity to multiple Tier 1 ISPs would help you to attract Internet traffic from your own BGP clients, making your company more profitable.
Unfortunately, while this design might look very appealing at first, there are some major drawbacks you need to consider:
You might not be able to negotiate an attractive per Mb transit rate, as your per-Tier 1 ISP traffic commitment in each of the regions will be relatively low.
Sub-optimal routing and possible high latency that you are likely to experience. Let’s explain technical reasons to why this might happen.
Let us consider a scenario where ISP-B’s client residing in the same geography as the “East” section of your network wants to communicate with you client. You’d achieve the lowest latency, if traffic from ISP-B would pass via ISP-C and enter your network as shown below:
Medium Size ISP – Suboptimal Upstream Peering
Unfortunately, this is unlikely to happen. For redundancy reasons, you should be advertising your “East” routes to “ISP-B” via the “West” peering point. And because the shortest AS-Path wins, default traffic flow will be as shown below:
Medium Size ISP – Suboptimal Upstream Peering
While this type of traffic flow might be acceptable, if your North / West / East regions are just a few miles away, it may pose a problem if there is a significant distance between them. Due to the speed of light limitations, distance always translates into packet latency.
You can try to manipulate your BGP advertisements towards upstream providers, setting AS-Prepend or sending BGP communities in the attempt to prevent this sub-optimal traffic flow from happening, but you are unlikely to find an acceptable remedy for this scenario. BGP protocol likes shortest AS Paths and ISPs prefer to send traffic to their directly connected clients instead of passing through a third party.
Instead of connecting to three different Service Providers across three geographical regions, you might be better off by picking just two transit providers, but connecting to both of these providers in all three geographies.
Medium Size ISP – Upstream Peering
Under normal conditions, you’d see the optimal traffic flow between the Global Internet and any of your regions. If one of the links were to fail, traffic to that ISP would reroute via two remaining links. This will increase end-to-end latency for some destinations, but this tradeoff should be acceptable.
Public Peering
As described in the “Pubic Peering” section of this paper, IXP locations are great places to establish direct connectivity to a large number of ISPs, Enterprises and CDN providers. As such, it is encouraged to be present at the public exchange points within ISP’s operating geography, and if cost permits, outside of operational boundaries. For example, service provider operating in Portugal, Spain and France should consider connecting to the largest European Peering points in Germany (DE-CIX), Amsterdam (AMX-IX) and London (LINX).
When establishing peering relationships, ISP should consider its own geography as well as peer’s geographical presence.
Figure below depicts potential peering scenario, where peering relationships could be established with “Public Peer – A” and “Public Peer – B”.
“Public Peer – A” operates in West and North regions, as well as some other geographies, not covered by you.
“Public Peer – B” operates in North and East regions, and also some other non-overlapping regions.
It should be no brainer to establish peering with “Public Peer – B” via “IXP-North” and “IXP-East”, as you would achieve optimal traffic flow between you two companies. Traffic originated from the West region will leverage IXP-North / IXP-East exchange points. This is acceptable as “Public Peer-B” is not present in the West.
Medium Size ISP – Upstream Peering
Decision to peer with “Public Peer – A” is more difficult. You can only peer at “IXP-West”, as “Public Peer – A” is not present at other exchange points. This will lead to sub-optimal traffic flow between your “North” customers and “Public Peer-A” customers located in the North region. You are almost guaranteed to achieve better performance by sending the North traffic via one of upstream providers. Recommended solution to this problem is to advertise a subset of your routes to “Public Peer – A”. Instead of sending all the routes originated by your company and your BGP downstream customers, only advertise the routes originated in the “West” region. The same should apply to the routes advertised by “Public Peer – A”. Request your partner to limit their advertisement to their Western routes. Use your transit provider to exchange traffic between “Peer-A” Northern region and your North and East areas.
Private Peering
Most of the service providers start their peering relationships at IXP and upon achieving certain traffic volume might later switch to a private peering arrangement. By switching to private links and bypassing IXP, they can both improve network availability and decrease traffic cost. Peering recommendations covered in Transit and Public sections of this document are also applicable to private peering arrangements. If companies operate in the same geographical regions, they should establish peering sessions in as many points as possible in order to minimize end-to-end latency.
It is not uncommon to see a connectivity scenario, where two companies leverage private connectivity arrangements in some areas, while relying on public peering in other areas. Even after building direct links to a peering partner, you can still maintain BGP sessions at public peering points, diversifying your connectivity. Obviously, you’ll need to manipulate BGP attributes to make sure that private links are preferred over public exchanges. Next diagram depicts such hybrid scenario.
Medium Size ISP – Private Peering
Private peering links were established in the East and West regions. In the West region, companies decided to preserve existing public peering relationships to maintain direct connectivity in case of the private link failure. Direct peering in the North was considered unfeasible due to low traffic volume. As such, two companies rely on “IXP-North” for local traffic exchange.
One final word of caution: when it comes to private connectivity – make sure you properly size your links. It is not uncommon to run into situations where direct private peering might become harmful. Let’s illustrate this with an example:
Our Medium-size ISP has two 100GE links per region to two transit providers. There are also 10GE links to IXP-West, IXP-North, IXP-West. While peering in these locations, Company XYZ was identified as a candidate for private peering connectivity. Netflow data shows that during peak hours, 300Mb/sec of traffic is being exchanged between the two companies. As a result, it is decided to build direct 1GE links in all three geographic regions. Everything works great until Company XYZ releases a new version of their software, and many customers on the Internet decide to download it at the same time. This causes a major congestion on private 1GE links. If companies were not to switch to the private peering and leveraged 10GE IXP connections instead, they would have easily coped with this sudden traffic increase.